Cluster de Alta Disponibilidad
Introducción
En este post vamos a ver instalar una aplicacioń php, en nuestro caso WordPress, sobre dos cluster de alta disponibilidad, uno con Keepalived y otro con Pacemaker.
Un cluster de alta disponibilidad es un conjunto de servidores que trabajan juntos para proporcionar un servicio de red, almacenamiento o aplicaciones. Los servidores de un cluster de alta disponibilidad se denominan nodos. Los nodos de un cluster de alta disponibilidad se configuran para que se comuniquen entre sí y para que trabajen juntos para proporcionar un servicio de red, almacenamiento o aplicaciones.
El escenario lo podemos encontrar en el siguiente repositorio, donde nos encontramos el vagrantfile necesario para crear las tres máquinas virtuales necesarias para el escenario y el playbook de ansible para instalar el cluster.
Construimos el escenario
Para construir el escenario, nos situamos en el directorio donde tenemos el vagrantfile y ejecutamos:
vagrant up
Una vez terminado el proceso, podemos comprobar que tenemos las tres máquinas virtuales creadas:
vagrant status
Nos desplazamos al directorio donde tenemos el playbook de ansible y ejecutamos:
ansible-playbook -b site.yaml
Comenzamos
Cluster de HA activo-pasivo
Tras levantar el escenario y aplicar la receta de ansible, podemos comprobar que se ha configurado correctamente el cluster y que los servicios se han instalado.
Para ello, nos conectamos al nodo1 y comprobamos el estado del cluster:
vagrant ssh nodo1
sudo su
pcs status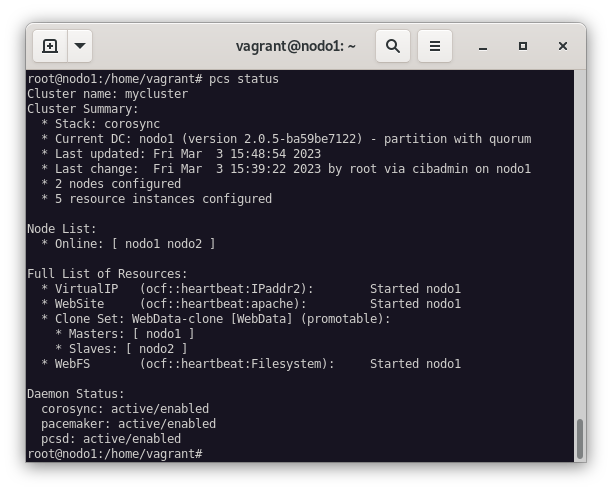
El siguiente paso es comprobar que podemos acceder a la web a través del navegador, deberemos cambiar la configuración de nuestra máquina host para que emplee la IP del nodo1 como servidor DNS, para ello, en el fichero /etc/resolv.conf añadimos la siguiente línea:
nameserver 192.168.121.48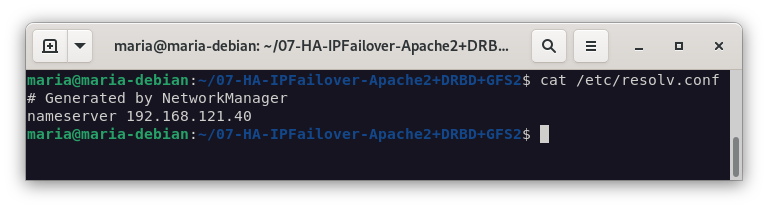
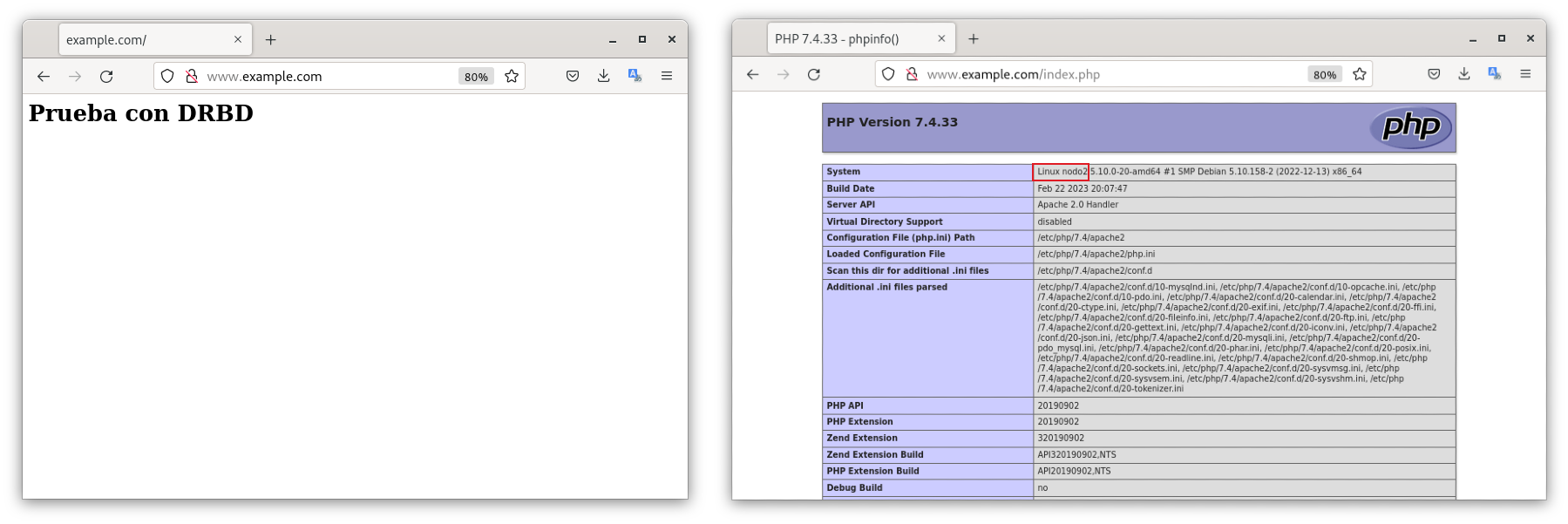
Si nos dirigimos a la url www.example.com/index.php, podemos ver que podemos acceder a la web y en el index.php podemos ver que efectivamente, está funcionando con el nodo1.
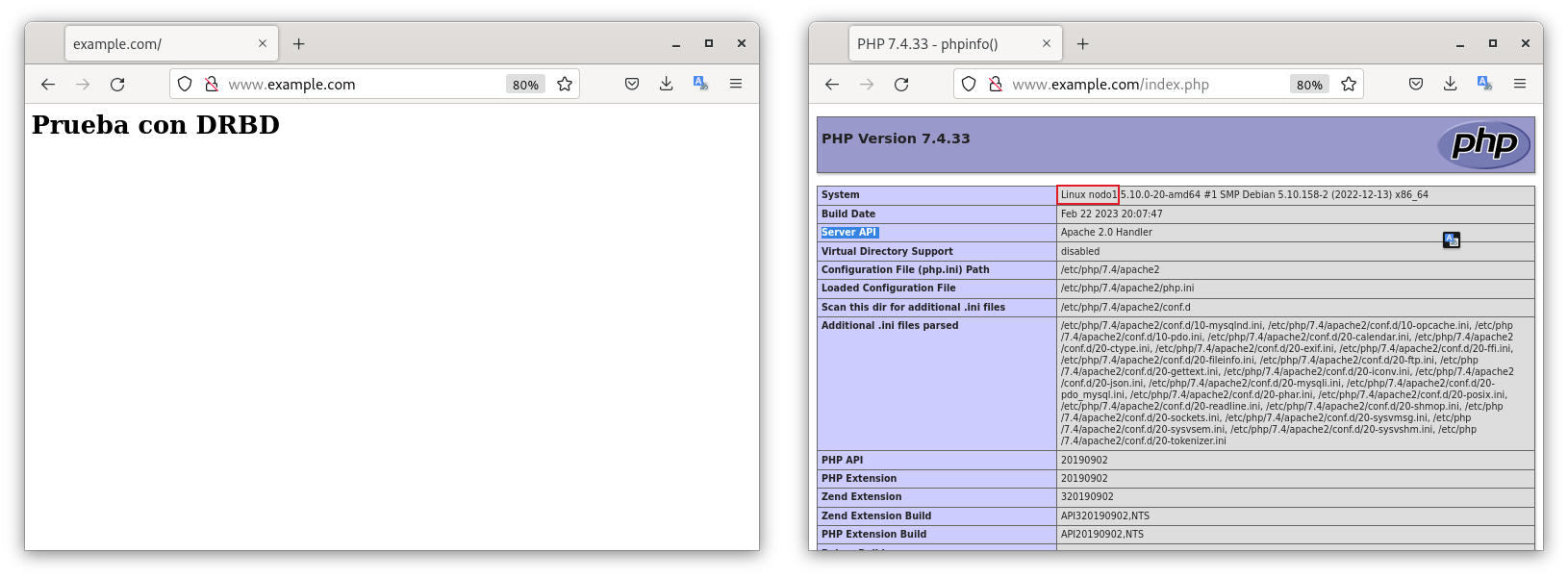
En caso que el nodo1 se apague, la web funcionará sobre el nodo2. Por ello, apagaremos de forma manual el nodo1.
Y cuando accedamos al index.php, y como podemos comprobar en la siguiente imagen, el servidor web está activo gracias al nodo2.
MariaDB Galera Cluster
Ahora instalaremos en los dos nodos un Galera MariaDB para emplearlo como base de datos en alta disponibilidad y que usará nuestro Wordpress, para ello, ejecutamos en ambos nodos el siguiente comando:
apt install mariadb-server
Para tener una base de datos segura, vamos a securizar mariadb de la siguiente manera:
mysql_secure_installationTras dejar a punto el gestor de base de datos, vamos a elegir un nodo, que en nuestro caso será el nodo 1, por lo que detenemos el servicio de mariadb:
systemctl stop mariadb.service
Y modificamos el fichero del cluster Galera de la siguiente manera:
nano /etc/mysql/mariadb.conf.d/60-galera.cnf[galera]
#Activa el cluster
wsrep_on = ON
#Nombre del cluster
wsrep_cluster_name = "MariaDB Galera Cluster"
#Ruta al módulo de Galera
wsrep_provider = /usr/lib/galera/libgalera_smm.so
#Dirección IP de los nodos participantes en el cluster
wsrep_cluster_address = gcomm://10.1.1.101,10.1.1.102
#Formato de binlog
binlog_format = row
#Motor de almacenamiento
default_storage_engine = InnoDB
#Tamaño del buffer de memoria
innodb_autoinc_lock_mode = 2
# Allow server to accept connections on all interfaces.
bind-address = 0.0.0.0
#Dirección IP del nodo cluster de la base de datos
wsrep_node_address=10.1.1.101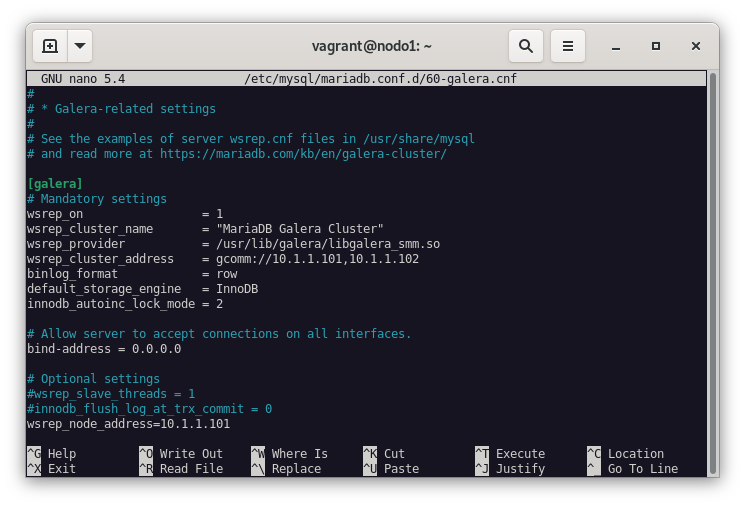
Creamos el cluster de la siguiente manera:
galera_new_clusterY arrancamos el servicio de mariadb:
systemctl start mariadb.service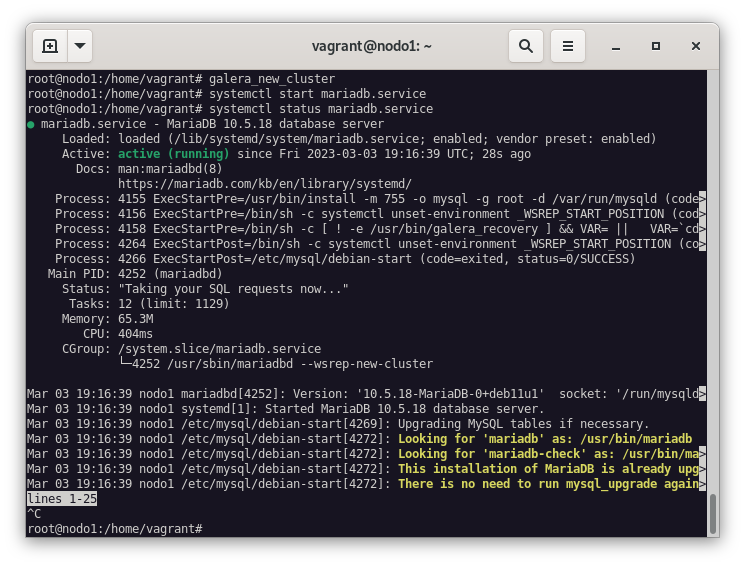
Para comprobar que el cluster está funcionando correctamente, ejecutamos el siguiente comando dentro de la base de datos:
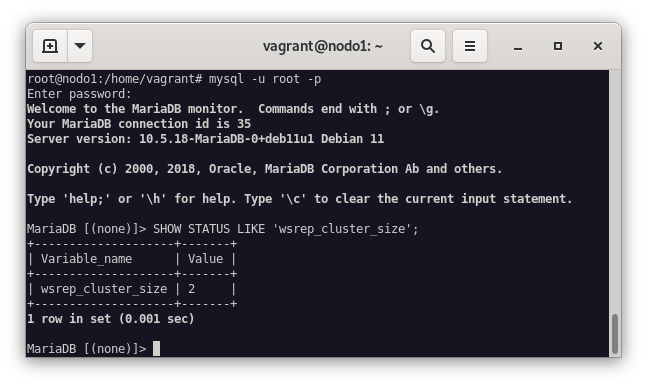
mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size'"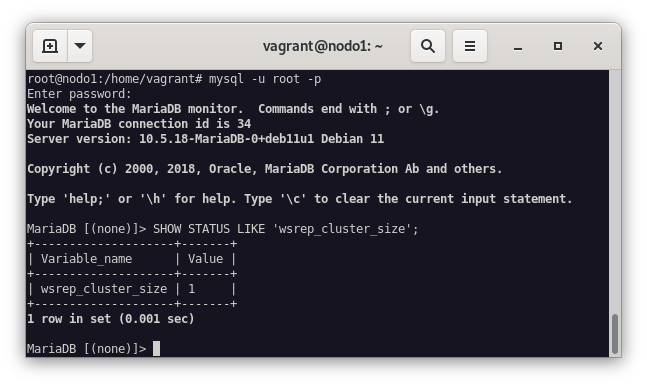
Como podemos ver en la imagen anterior, el cluster está formado por un nodo, por lo que ahora vamos a añadir el nodo2 al cluster. Realizamos los mismos pasos que en el nodo1, pero en este caso, cambiamos la dirección IP del nodo2 en el fichero de configuración del cluster.
[galera]
#Activa el cluster
wsrep_on = 1
#Nombre del cluster
wsrep_cluster_name = "MariaDB Galera Cluster"
#Ruta al módulo de Galera
wsrep_provider = /usr/lib/galera/libgalera_smm.so
#Dirección IP de los nodos participantes en el cluster
wsrep_cluster_address = gcomm://10.1.1.101,10.1.1.102
binlog_format = row
#Motor de almacenamiento
default_storage_engine = InnoDB
#Tamaño del buffer de memoria
innodb_autoinc_lock_mode = 2
# Allow server to accept connections on all interfaces.
bind-address = 0.0.0.0
#Dirección IP del nodo cluster de la base de datos
wsrep_node_address=10.1.1.102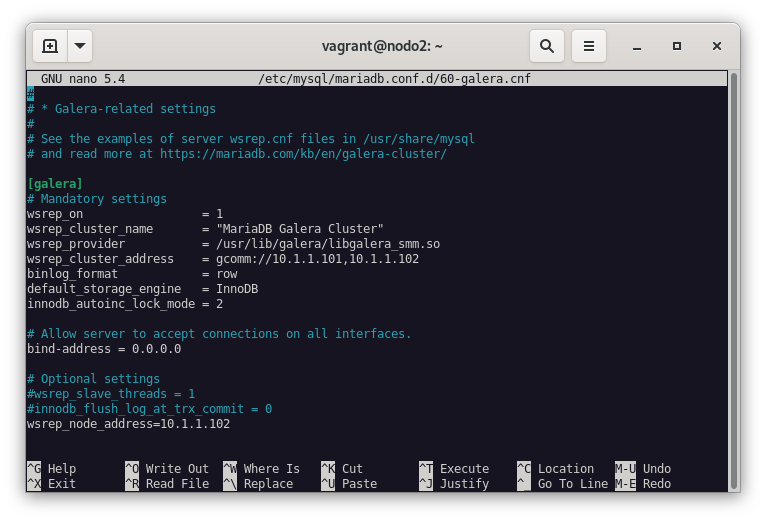
Y arrancamos el servicio de mariadb:
systemctl start mariadb.service
Ahora, ejecutamos de nuevo el comando mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size'" para comprobar que el cluster está formado por dos nodos.
Ya comprobado que nuestro cluster de mariadb Galera funciona correctamente, vamos a crear una base de datos y un usuario para que el wordpress pueda acceder a ella.
CREATE DATABASE wordpress;
GRANT ALL ON wordpress.* TO 'wordpress'@'%' IDENTIFIED BY 'wordpress';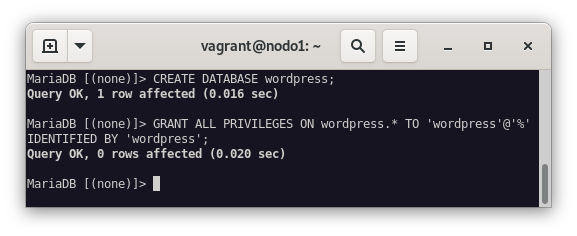
Wordpress
Ahora le toca el turno a wordpres, por lo que nos lo vamos a descargar en el nodo 1. Navegamos a la carpeta /var/www/html y ejecutamos el siguiente comando:
wget https://es.wordpress.org/latest-es_ES.tar.gz
Lo descomprimimos, y le cambiamos el propietario a www-data:
tar -xvzf latest-es_ES.tar.gz
chown -R www-data: wordpress/
Accedemos a https://www.example.com/wordress e instalamos wordpress:
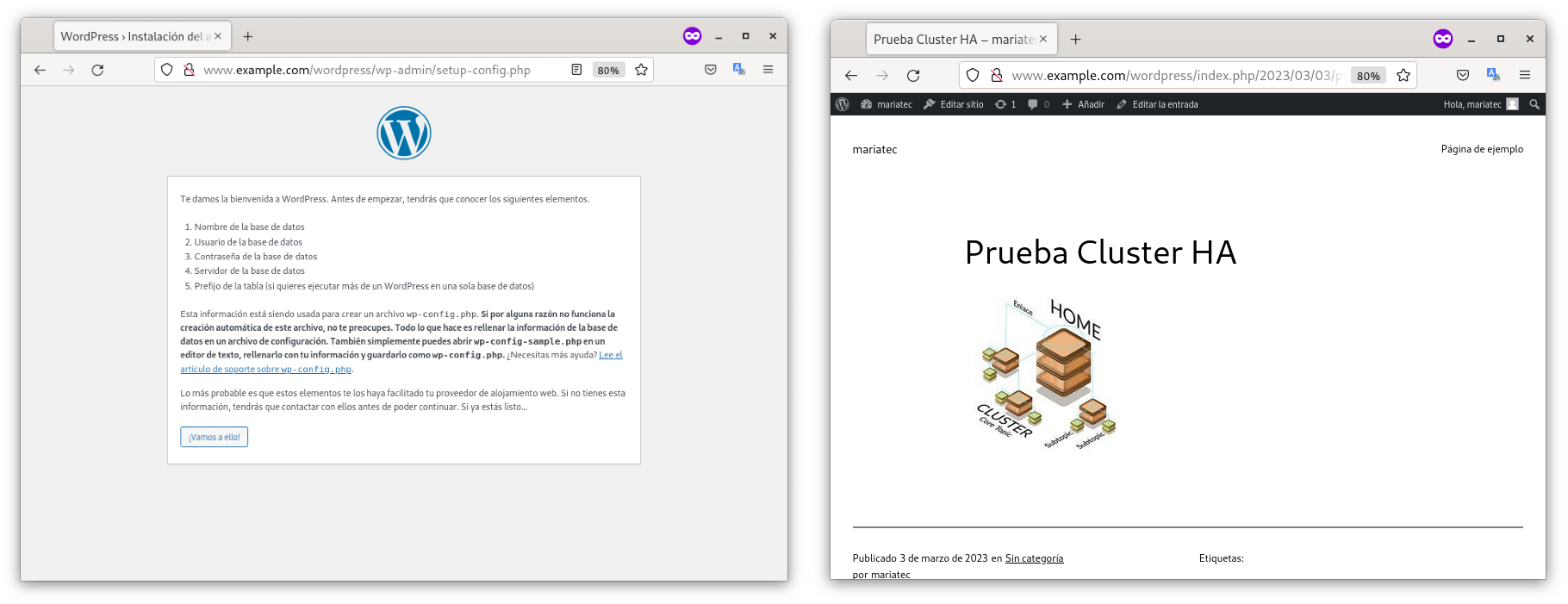
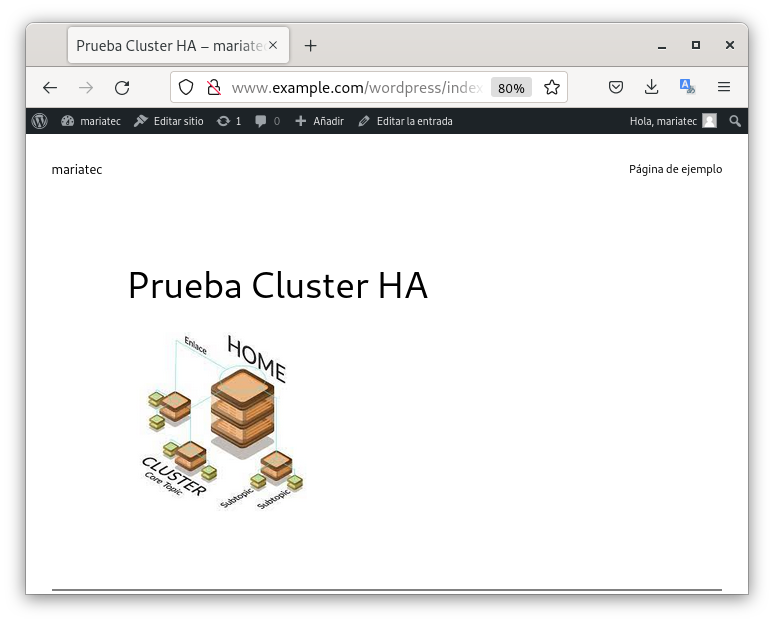
Como podemos ver en la imagen anterior, está instalado y le hemos añadido una nueva entrada.
Comprobar Alta disponibilidad
Si apagásemos el nodo1, todos los recursos de este nodo deberían de pasar al nodo2, y por ello vamos a comprobarlo:
-
Apagamos nodo1 y verificamos en el nodo2 el estado del cluster:
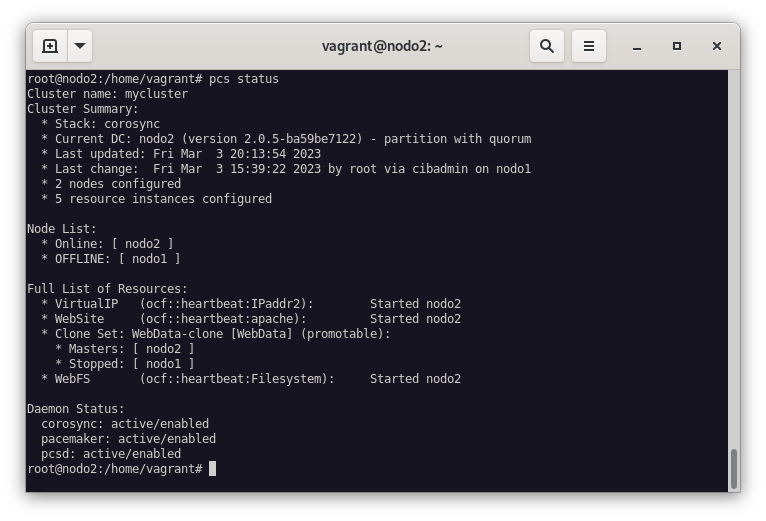
Como podemos ver, se hemos podido acceder a nuestra nueva entrada y por ello, podemos verificar, que la configuración de nuestra cluster en alta disponibilidad, con una aplicación php y una base de datos, funciona correctamente.
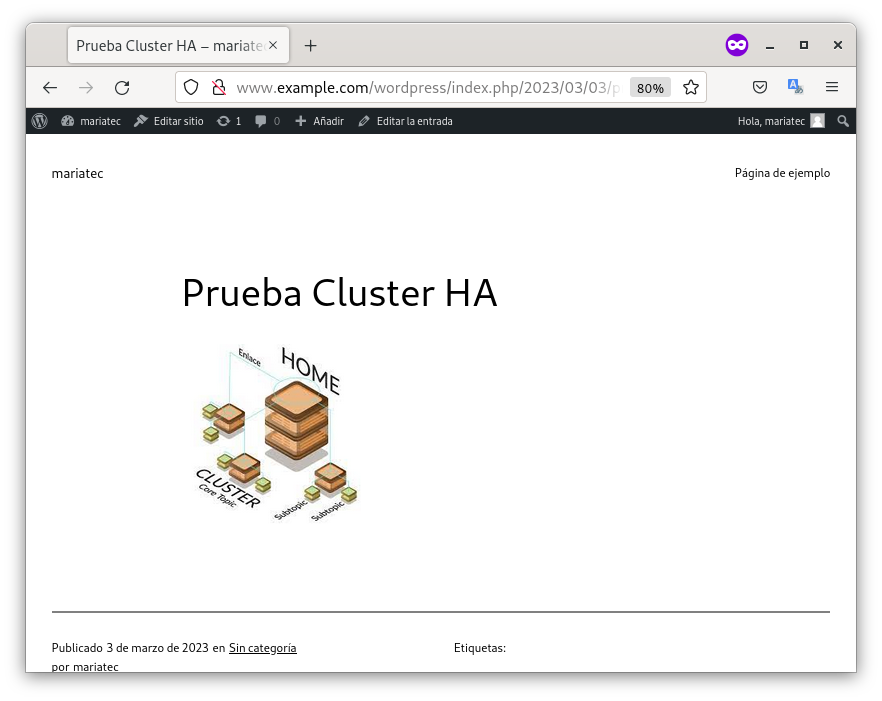
Cluster de HA activo-activo
Siguiendo las instrucciones que encontraremos en el escenario 7, convertiremos el clúster en activo-activo. Vamos a instalar el fencing para que el clúster funcione de manera adecuada.
Partiendo del ejercicio anterior, donde hemos configurado un cluster de IP Failover + Apache2 + DRBD, vamos a agregar un sistema de almacenamiento distribuido GFS2, por lo que podremos configurar nuestros sistema DRBD como Dual-primary, y la IP ClusterIP podrá estar asignado a cualquiera de los nodos, ya que los nodos podrán escribir o leer al mismo tiempo.
En definitiva, vamos a convertir nuestro clúster en activo-activo.
Instalación de GFS2
En este apartado vamos a configurar GFS2 como sistema de almacenamiento distribuido para conseguir el cluster de alta disponibilidad activo-activo.
Además vamos a instalar el programa DLM (Distributed Lock Manager) que será el encargado de gestionar el acceso del clúster al almacenamiento distribuido.
En los dos nodos, instalamos el paquete gfs2-utils y dlm:
apt-get install gfs2-utils dlm-controld
El DLM se tiene que ejecutar en los dos nodos, vamos a crear un recurso ocf:pacemaker:controld y lo vamos a clonar. Para ello, nos dirigimos a la consola del nodo1 y ejecutamos el siguiente comando:
pcs cluster cib dlm_cfg
pcs -f dlm_cfg resource create dlm ocf:pacemaker:controld op monitor interval=60s
pcs -f dlm_cfg resource clone dlm clone-max=2 clone-node-max=1
pcs cluster cib-push dlm_cfg --config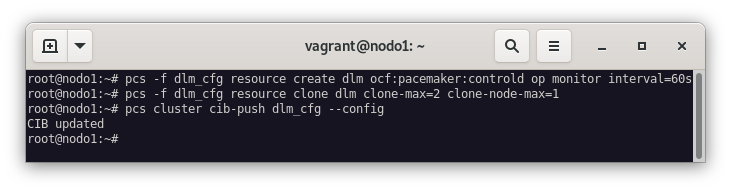
Comrpobamos que el recurso se ha creado correctamente:
pcs status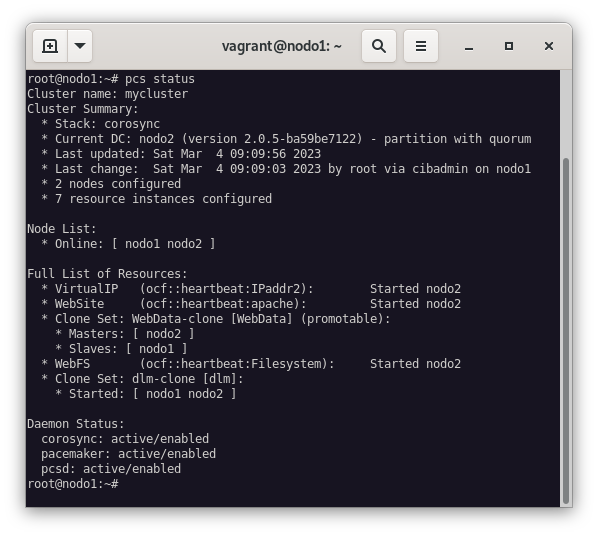
Creamos el sistema de archivos GFS2
Antes de continuar, vamos a deshabilitar el recurso que controlaba el sistema de archivo del ejercicio anterior:
pcs resource disable WebFSY veremos como los recursos WebFS y WebSite se han detenido:
pcs status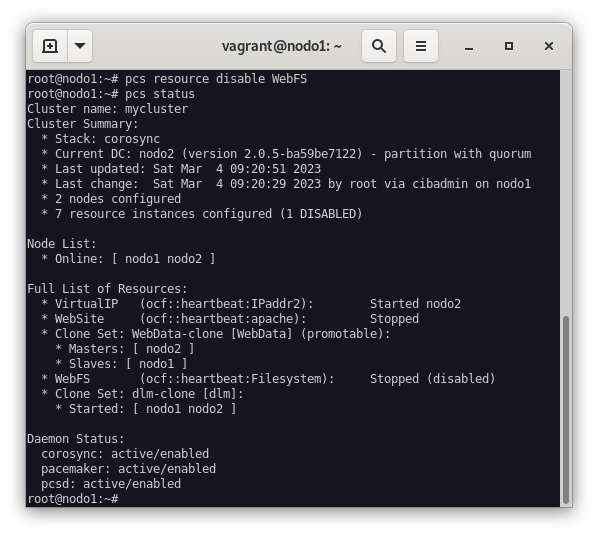
El siguiente paso será formatear el dispositivo de bloques del nodo1 con el siguiente comando:
mkfs.gfs2 -p lock_dlm -j 2 -t mycluster:web /dev/drbd1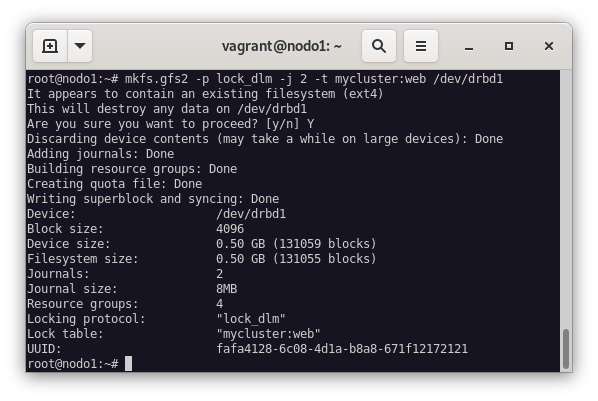
Las opciones que hemos utilizado son:
-p lock_dlm: Indica que vamos a usar el programa DLM (Distributed Lock Manager) para gestionar los cambiso del sistema de archivo.-j 2: Se va a reservar espacio para 2 journals (registro donde se almacena información necesaria para recuperar los datos afectados por una transición en caso de que falle) uno para cada nodo.-t mycluster:web: El nombre de la tabla de bloqueo (lock) (web) en el clustermycluster(nombre del cluster que indicamos al crearlo con corosync y que lo podemos encontrar en/etc/corosync/corosync.conf).
A continuación, vamos a guardar la información en el dispositivo de bloques. Creamos el fichero index.html:
mount /dev/drbd1 /mnt
cd /mnt
echo "<h1>Prueba con GFS2</h1>" >> index.html
cd
umount /mnt
Una vez terminado esto, vamos a reconfigurar el recurso WebFS del cluster con el nuevo sistema de fichero que hemos configurado:
pcs resource update WebFS fstype=gfs2Y como va a necesitr que DLM esté activado, tenemos que añadir dos restricciones: la primera es para que el recurso WebFS se ejecute en el mismo nodo que el recurso dlm-clone, y la segunda es para que el recurso dlm-clone se ejecute antes que el recurso WebFS.
pcs constraint colocation add WebFS with dlm-clone INFINITY
pcs constraint order dlm-clone then WebFS
El último paso que nos queda para terminar de configurar el sistema de archivos GFS2, es montar el sistema de archivos en los dos nodos y reconfigurar el recurso WebData-clone indicando que se ejecuten como primario en el DRBD.
pcs cluster cib active_cfg
pcs -f active_cfg resource clone WebFS
pcs -f active_cfg constraint
pcs -f active_cfg resource update WebData-clone promoted-max=2
pcs cluster cib-push active_cfg --config
pcs resource enable WebFS
En este momento tenemos el DRBD como dual-primary y el sistema de ficheros GFS2 montado en los dos nodos. Cualquiera de los servidores web pueden escribir ficheros en /var/www/html, por lo que podemos clonar el recurso WebSite y quitar la restricción de colocación que hacía que el servidor web se activa en el nodo que tenía asignada la VirtualIP. Para ello:
pcs cluster cib active_cfg
pcs -f active_cfg resource clone WebSite
pcs cluster cib-push active_cfg --config
pcs constraint colocation delete WebSite-clone VirtualIP
Si realizamos un pcs status veremos que el recurso WebSite se ha clonado y que la IP ClusterIP se ha asignado a ambos nodos, y podemos ver que está activo:
pcs status
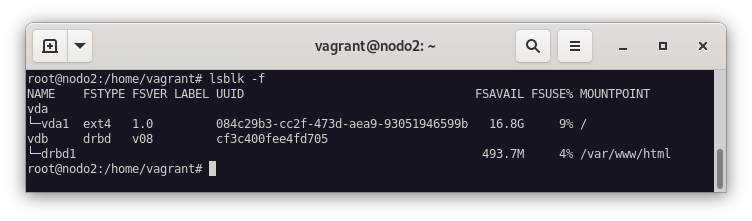
lsblk -f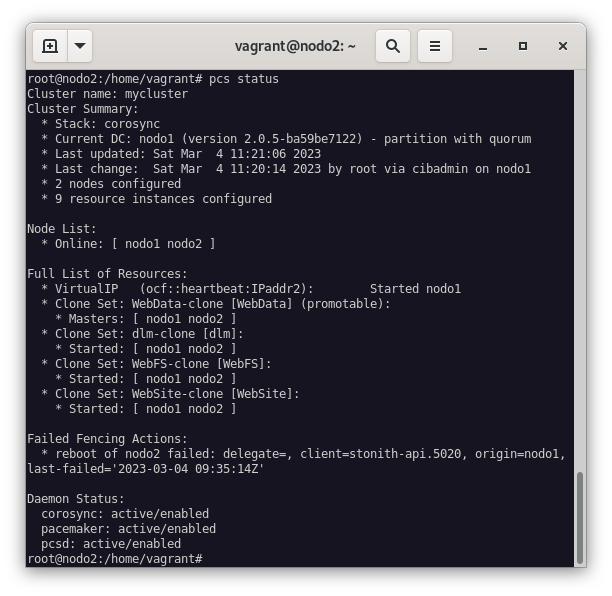
Ahora, solo queda configurar el Fencing para que en caso de fallo de un nodo, se pueda recuperar el servicio, y el STONITH para que en caso de fallo de un nodo, se pueda recuperar el servicio y que el nodo que ha fallado se pueda recuperar. Para ver los agentes que tenemos disponibles, ejecutamos el siguiente comando:
pcs stonith list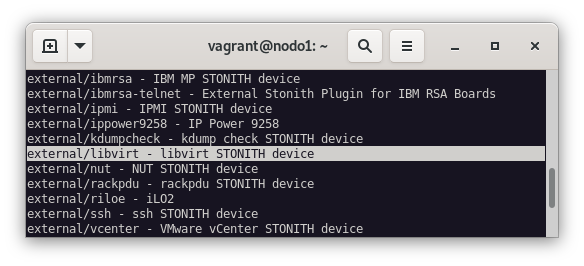
Al estar usando KVM como hipervisor, vamos a hacer uso del external/libvirt para el STONITH. Para ello, vamos a instalar el paquete libvirt-clients:
apt-get install libvirt-clients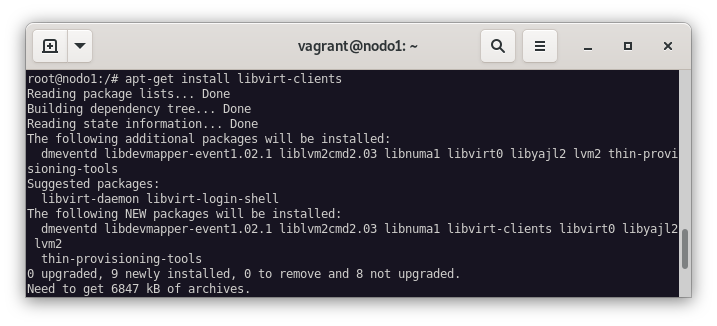
Ambos nodos deberán de ser capaces de acceder al host a través de SSH, generaremos el par de claves en ambos nodos y las añadimos al fichero de authorized_keys del host:
ssh-keygen -t rsa
ssh-copy-id 192.168.121.1
Comprobamos que los parámetros que necesitamos para configurar el STONITH están bien:
pcs stonith describe external/libvirtComo vemos en la siguiente imagen, hemos de indicar dos parámetros de forma obligatoria:
hostlist: Lista de nodos que se van a utilizar para elSTONITH.
hostlist="nodo1:06-HA-IPFailover-Apache2DRBDGFS2_nodo1,nodo2:06-HA-IPFailover-Apache2DRBDGFS2_nodo2"
hypervisor_uri: URI del servidor KVM.
hypervisor_uri="qemu+ssh://192.168.121.1/system"
Ya tenemos todo configurado para poder hacer uso del STONITH. Solo nos resta habilitar el Fencing en el cluster:
pcs cluster cib stonith_cfg
pcs -f stonith_cfg stonith create fencing-libvirt external/libvirt \
hostlist="nodo1:06-HA-IPFailover-Apache2DRBDGFS2_nodo1,nodo2:06-HA-IPFailover-Apache2DRBDGFS2_nodo2" \
hypervisor_uri="qemu+ssh://192.168.121.1/system"
pcs -f stonith_cfg property set stonith-enabled=true
pcs cluster cib-push stonith_cfg --config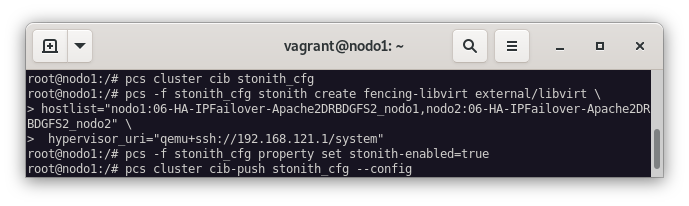
Prueba de funcionamiento
Para poder realizar las pruebas de funcionamiento del cluster, vamos a volver a instalar Wordpress, dado que al formatear el dispositivo de bloques hemos perdido toda la información que teníamos en el sistema de ficheros. Sólo debemos realizar los pasos que hemos realizado en el apartado Instalación de Wordpress. La información no es necesario recuperarla porque está guardada en la base de datos, por lo que solo debemos configurar de nuevo las variables de la base de datos que ya teníamos de antemano.
Una vez instalado Wordpress, accederemos a la página y veremos que el post sigue existiendo. La imagen he tenido que añadirla de nuevo, dado que no se había guardado en la base de datos, pero el post existía.
Balanceador de carga
Para que el balanceador de carga, vamos a instalar un HAproxy en el nodo dns y lo configuraremos de la siguiente forma:
apt install haproxynano /etc/haproxy/haproxy.cfgfrontend servidores_web
bind *:80
mode http
stats enable
stats uri /ha_stats
stats auth cda:cda
default_backend servidores_web_backend
backend servidores_web_backend
mode http
balance roundrobin
server backend1 10.1.1.101:80 check
server backend2 10.1.1.102:80 check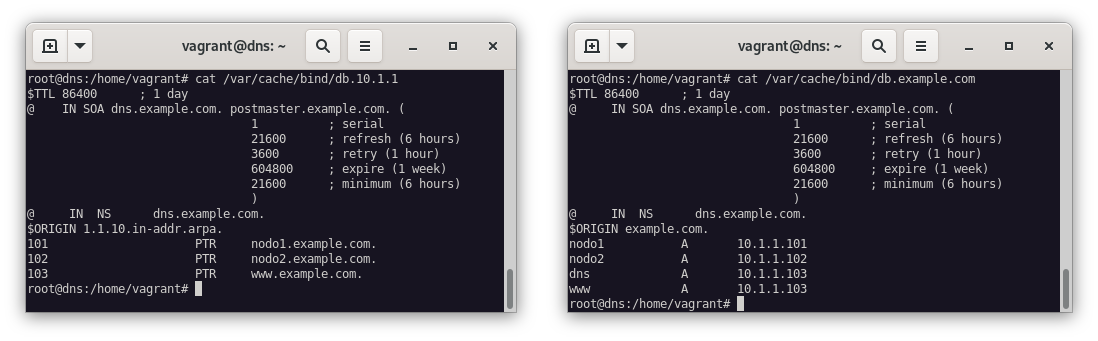
Realizado esto, también modificaremos las zonas dns, y para ello, debemos modificar los siguientes ficheros de configuración de las zonas dns:
nano /var/cache/bind/db.10.1.1
###
103 PTR www.example.comnano /var/cache/bind/db.example.com
###
www PTR 10.1.1.103Tras estas modificaciones, deberemos reiniciar el servicio bind9 para que se apliquen los cambios:
systemctl restart bind9Solo nos queda comprobar que podemos acceder a la web: