Copias de Seguridad y Restauración
Introducción
En este post vamos a ver como hacer copias de seguridad y restauraciones de bases de datos, tanto en Orable, Postgres, MySQL y MongoDB.
Cuando hablamos de copias de seguridad, nos referimos a la copia de los datos de una base de datos, para poder restaurarlos en caso de que se produzca algún fallo en la base de datos, es decir, una recuperación de los datos ante cualquier situación de desastres.
Las copias de seguridad las podemos realizar de dos formas:
-
En frio: Se realiza cuando la base de datos está apagada, y se realiza una copia de los ficheros de datos y de control de la base de datos. El inconveniente de este tipo de copias de seguridad, es que no se puede hacer uso del servicio mientras se realiza la copia de seguridad.
-
En caliente: Se realiza cuando la base de datos está en funcionamiento, y se realiza una copia de los ficheros de datos y de control de la base de datos.
Ejercicios prácticos

Ejercicio 1
Realiza una copia de seguridad lógica de tu base de datos completa, teniendo en cuenta los siguientes requisitos:
- La copia debe estar encriptada y comprimida.
- Debe realizarse en un conjunto de ficheros con un tamaño máximo de 60 MB.
- Programa la operación para que se repita cada día a una hora determinada.
Para realizar la copia de seguridad lógica, vamos a utilizar la herramienta RMAN, que es la herramienta de copia de seguridad y restauración de Oracle.
Para ello, primero vamos a crear un directorio para almacenar los backups, y vamos a darle permisos al usuario oracle para que pueda escribir en el directorio.
mkdir /opt/oracle/backup
chown oracle:oinstall /opt/oracle/backup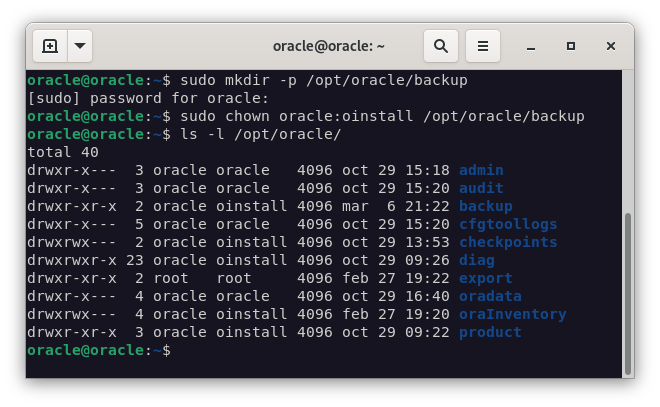
Nos conectamos a la base de datos y creamos un directorio en el que se almacenarán los archivos de exportación, al que le asignaremos los permisos necesarios para que el usuario scott pueda acceder a él.
CREATE DIRECTORY EXPORT_DIR AS '/opt/oracle/backup';
GRANT READ, WRITE ON DIRECTORY EXPORT_DIR TO scott;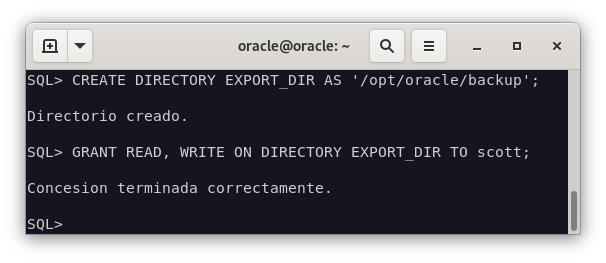
Le adjudicamos también permisos para que pueda exportar los datos.
GRANT DATAPUMP_EXP_FULL_DATABASE TO scott;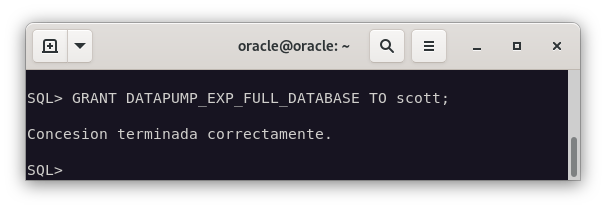
Ahora vamos a crear un script que realice la copia de seguridad lógica de la base de datos.
expdp scott/tigger DIRECTORY=EXPORT_DIR DUMPFILE=backup`date +%Y%m%d`.dmp FULL=YES LOGFILE=backup`date +%Y%m%d`.log COMPRESSION=ALL DUMPFILE=compress.dmp FILESIZE=60M ENCRYPTION_PASSWORD=tigger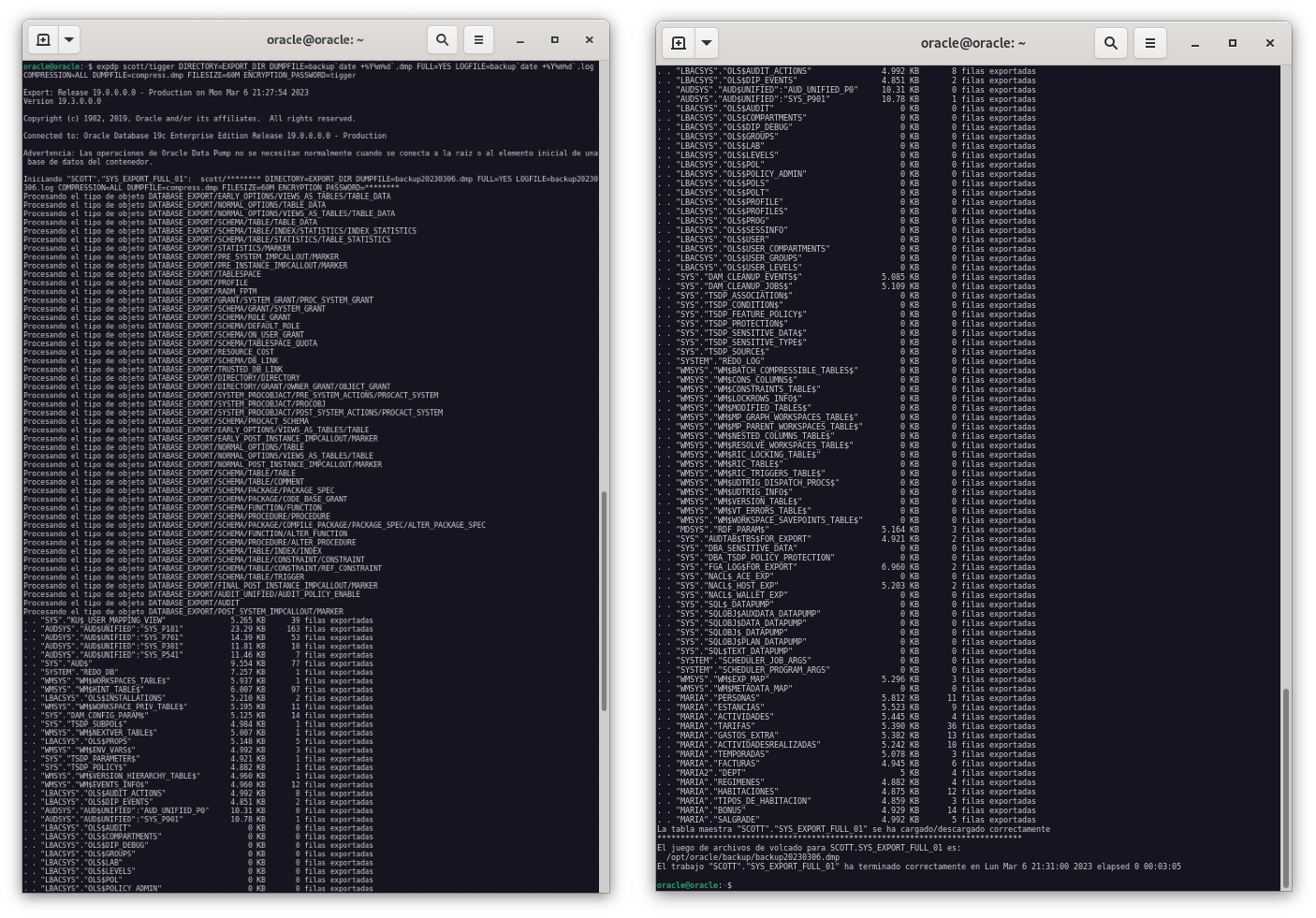
Los parámetros que hemos utilizado son los siguientes:
| Parámetro | Descripción |
|---|---|
| scott | Usuario que realiza la copia de seguridad |
| tigger | Contraseña del usuario |
| DIRECTORY=EXPORT_DIR | Directorio donde se almacenará la copia de seguridad |
DUMPFILE=backupdate +%Y%m%d.dmp |
Fichero donde se almacenará la copia de seguridad junto con su fecha |
| FULL=YES | Indica que se realiza una copia de seguridad completa |
LOGFILE=backupdate +%Y%m%d.log |
Fichero donde se almacenará el log de la copia de seguridad junto con su fecha |
| COMPRESSION=ALL | Indica que se comprime la copia de seguridad |
| DUMPFILE=compress.dmp | Fichero donde se almacenará la copia de seguridad comprimida |
| FILESIZE=60M | Tamaño máximo de los ficheros de la copia de seguridad |
| ENCRYPTION_PASSWORD=tigger | Contraseña para encriptar la copia de seguridad |
Como podemos ver en la imagen, se han creado 3 ficheros:
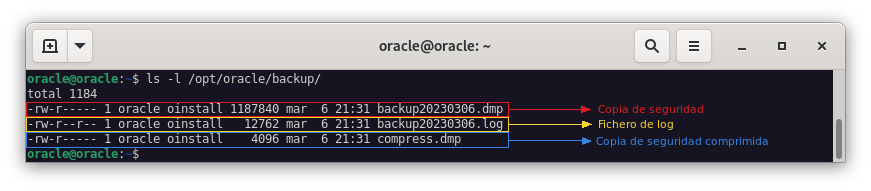
Ejercicio 2
Restaura la copia de seguridad lógica creada en el punto anterior.
Para probar la eficacia de la copia de seguridad, vamos a eliminar dos tablas de dos bases de datos diferentes.
DROP TABLE maria2.dept;
DROP TABLE maria.salgrade;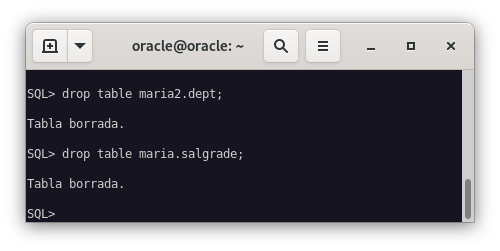
Una vez que hemos hecho la eliminación de ambas tablas, vamos a realizar una restauración de la copia de seguridad. NOTA: No nos olvidemos de poner la contraseña de encriptación, ya que en caso contrario, no nos dejará restaurar la copia de seguridad.
impdp scott/tigger DIRECTORY=EXPORT_DIR DUMPFILE=backup20230306.dmp FULL=YES ENCRYPTION_PASSWORD=tigger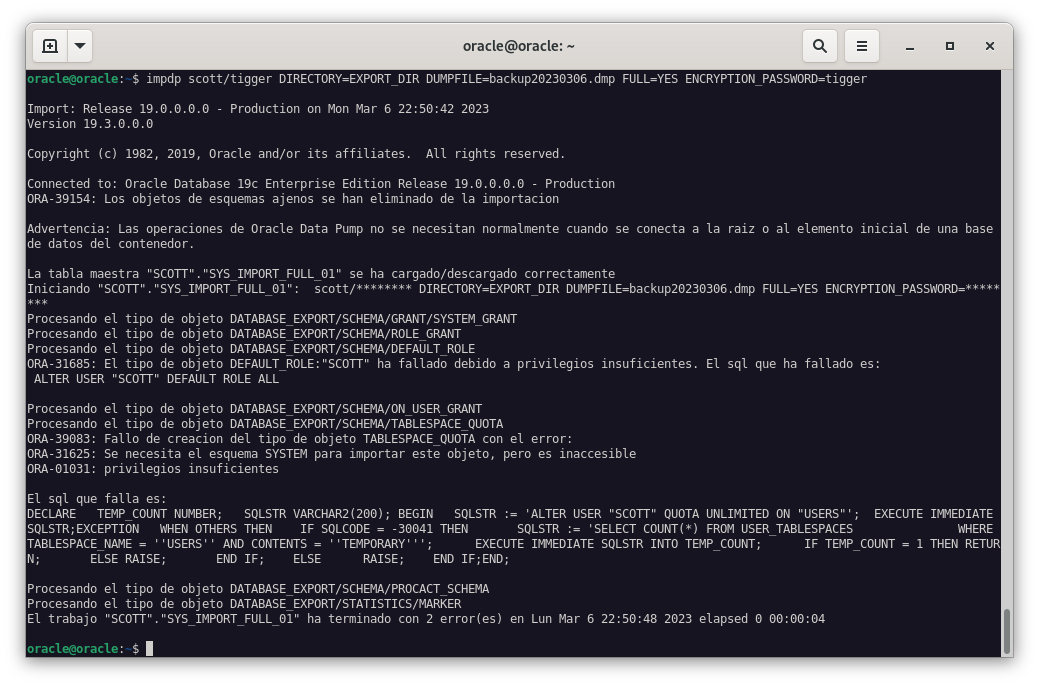
Y como podemos ver, se han restaurado las tablas que habíamos eliminado.
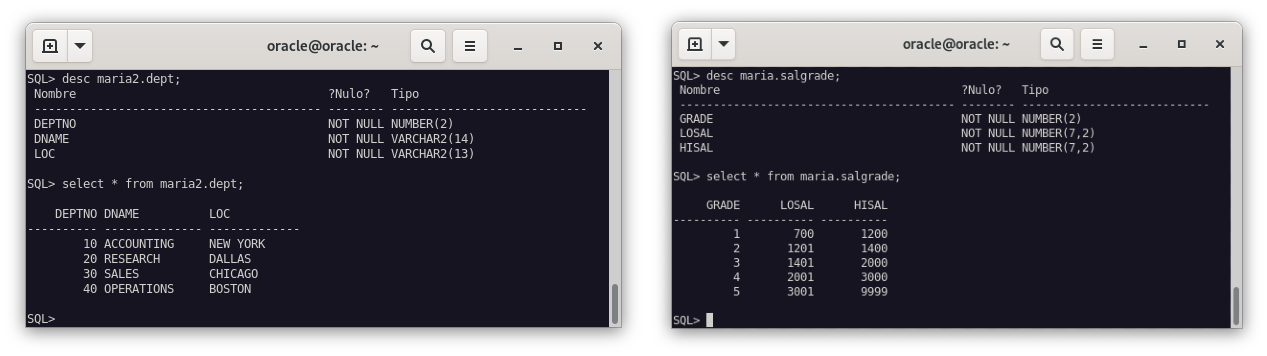
Ejercicio 3
Pon tu base de datos en modo ArchiveLog y realiza con RMAN una copia de seguridad física en caliente.
Como podemos recordar, en el ejercicio anterior, hemos realizado una copia de seguridad lógica de la base de datos, y ahora vamos a restaurarla.
Para restaurar la base de datos, debemos hacerlo en modo ArchiveLog, pero ¿qué es el modo ArchiveLog?
El modo ArchiveLog es un modo de operación de Oracle que permite que la base de datos pueda recuperarse de un fallo, ya sea por un fallo del sistema o por un fallo del usuario. Para ello, Oracle guarda los cambios que se realizan en la base de datos en un fichero de log, que se llama Archivelog. Cuando se produce un fallo, Oracle puede recuperar la base de datos a partir de los ficheros de log.
Para activar el modo ArchiveLog, debemos realizar una serie de pasos:
- Paramos la base de datos.
sqlplus / as sysdba
shutdown immediate;- Iniciamos la base de datos:
Startup mount;- Modificamos la base de datos para que se ejecute en modo
ArchiveLog:
ALTER DATABASE ARCHIVELOG;- Y por último, iniciamos la base de datos en modo
ArchiveLog:
ALTER DATABASE OPEN;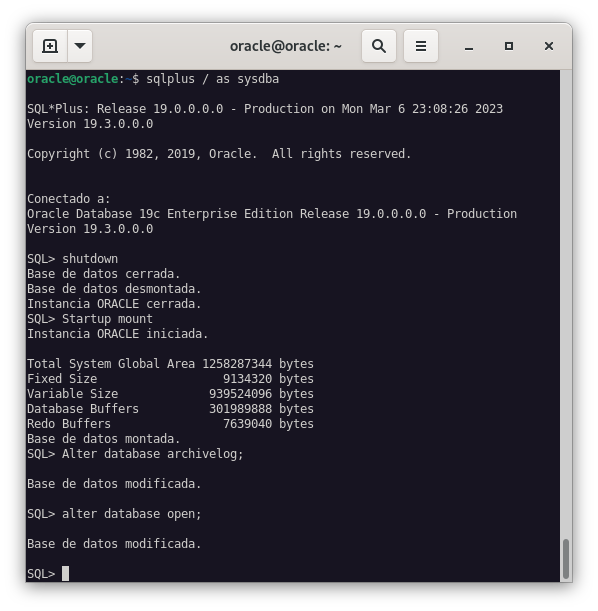
En la imagen podemos ver que los comandos han funcionado correctamente, pero la verdadera prueba de fuego es ejecutando en el cliente de Oracle el comando select log_mode from v$database; y comprobar que nos devuelve ARCHIVELOG.
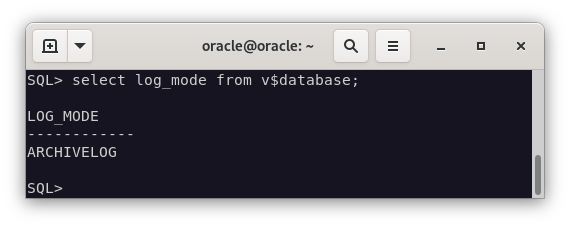
Y efectivamente, nos devuelve ARCHIVELOG, por lo que ya podríamos realizar la copia de seguridad.
La copia de seguridad la vamos a realizar con el comando RMAN, que es el comando de Oracle para realizar copias de seguridad.
RMAN (Recovery Manager) es una herramienta de Oracle que nos permite realizar copias de seguridad de la base de datos, restaurar la base de datos, realizar copias de seguridad de los ficheros de log, etc. Una estrategia completa de alta disponibilidad y recuperación ante desastres requiere procedimientos confiables de copia de seguridad, restauración y recuperación de datos. Oracle Recovery Manager (RMAN) proporciona una base integral para realizar copias de seguridad y recuperar de manera eficiente la base de datos de Oracle. Está diseñado para trabajar íntimamente con el servidor, proporcionando detección de corrupción a nivel de bloque durante la copia de seguridad y la restauración. RMAN optimiza el rendimiento y el consumo de espacio durante el respaldo con multiplexación de archivos y compresión de conjuntos de respaldo, y se integra con Oracle Secure Backup, así como con productos de administración de medios de terceros, para respaldo en cinta.
RMAN se ocupa de todos los procedimientos de base de datos subyacentes antes y después de la copia de seguridad o la restauración, lo que libera la dependencia del sistema operativo y los scripts SQL*Plus. Proporciona una interfaz común, a través de la línea de comandos y Enterprise Manager, para tareas de copia de seguridad en diferentes sistemas operativos host y ofrece funciones que no están disponibles a través de métodos administrados por el usuario, como la paralelización de flujos de datos de copia de seguridad/restauración, política de retención de archivos de copia de seguridad e historial detallado. de todas las copias de seguridad.
Y tras esta mediana introducción, vamos a realizar la copia de seguridad. Para ello, iniciaremos rman y nos conectaremos a la base de datos.
rman
connect target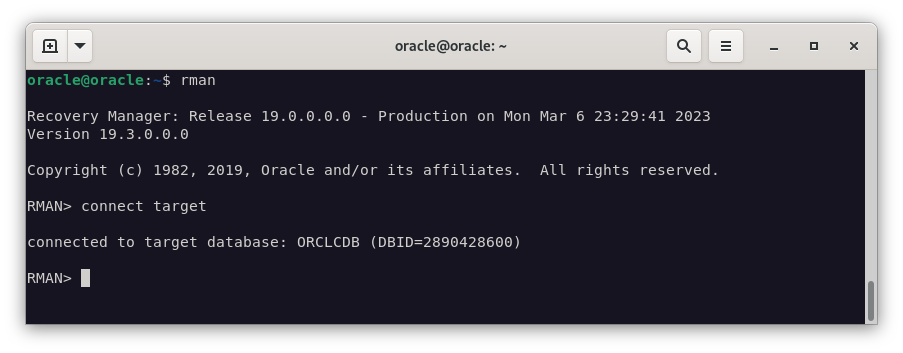
Una vez conectados, nos vamos a configurar la ruta a la que vamos a guardar la copia de seguridad. Para ello, ejecutamos el comando configure.
configure channel device type disk format '/opt/oracle/rman';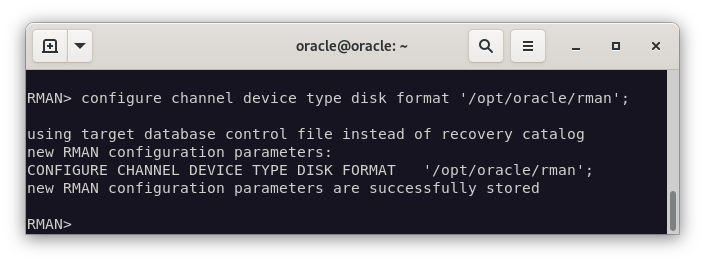
Tras ello, lo que nos queda realizar el backup de la base de datos ejecutando el siguiente comando dentro de rman:
bakcup database; Ejercicio 4
Borra un fichero de datos de un tablespace e intenta recuperar la instancia de la base de datos a partir de la copia de seguridad creada en el punto anterior.
Ejercicio 5
Borra un fichero de control e intenta recuperar la base de datos a partir de la copia de seguridad creada en el punto anterior.

Ejercicio 6
Documenta el empleo de las herramientas de copia de seguridad y restauración de Postgres.
En Postgres, podemos realizar dos tipos de backups:
El primero del que vamos a hablar es el bakcup lógico. Estos utilizan el procedimiento SQL Dump, Que consiste en recorrer de forma ordenada los objetos de ka base de datos y realizar el volcado de las sentencias SQL necesarias para su recreación. Un factor a favor de este tipo de backups es que se restaurar sobre cualquier instancia, es decir, no es necesario que el sistema operativo sea el mismo, ni la arquitectura o la versión de PostgresSQL.
Los ficheros son legibles, por lo que se pueden editar y modificar, cosa que puede ser una ventaja o una desventaja, dependiendo de lo que se quiera hacer. Tampoco será necesario parar la instancia, dado que el servicio no se verá interrumpido.
Hemos hablado de las ventajas, pero no siempre todo es así. La principal de ellas es que no se permite la recuperación de la misma hasta un punto determinado en el tiempo, sino que se realiza hasta el último punto de backup. Esto puede ser un problema, ya que si se ha realizado un backup cada hora, y se ha producido un fallo en la base de datos, se perderán las últimas 23 horas de trabajo.
Para realizar backups lógicos, podemos utilizar dos herramientas:
-
pg_dumpall: Esta herramienta nos permite hacer backups de un cluster completo, es decir, de todas las bases de datos que se encuentren en el cluster. Por lo que este tipo no es un backup de una base de datos en concreto, sino de todas las que se encuentren en el cluster. La recuperación tampoco sería selectiva, sino que se restauraría todo el cluster. Y como el fichero es un script SQL, podemos utilizar la consola de comandos de Postgres para ejecutarlo.
Es una utilidad para escribir (“volcar”) todas las bases de datos PostgreSQL de un clúster en un archivo de script. El archivo de script contiene comandos SQL que se pueden usar como entrada para psql para restaurar las bases de datos. Lo hace llamando a pg_dump para cada base de datos en el clúster. pg_dumpall también vuelca objetos globales que son comunes a todas las bases de datos, a saber, roles de base de datos, espacios de tablas y concesiones de privilegios para parámetros de configuración. (pg_dump no guarda estos objetos).
Dado que pg_dumpall lee tablas de todas las bases de datos, lo más probable es que tenga que conectarse como superusuario de la base de datos para producir un volcado completo. También necesitará privilegios de superusuario para ejecutar el script guardado para poder agregar roles y crear bases de datos.
El script SQL se escribirá en la salida estándar. pg_dumpall necesita conectarse varias veces al servidor PostgreSQL (una vez por base de datos). Si utiliza la autenticación de contraseña, le pedirá una contraseña cada vez. Es conveniente tener un archivo ~/.pgpass en tales casos. Si no se especifica ningún nombre de archivo, pg_dumpall escribirá en la salida estándar.
Algunas de las opciones que podemos utilizar son:
Opción Descripción -a, –data-only No volcar los esquemas, solo los datos. -c, –clean Agregar comandos para eliminar objetos antes de crearlos. -C, –create Agregar comandos para crear la base de datos y los roles de base de datos. -d, –dbname=DATABASE Nombre de la base de datos a volcar. -f, –file=FILENAME Escribir el volcado a un archivo en lugar de la salida estándar. -h, –host=HOSTNAME Nombre del host del servidor de base de datos. -n, –schema=SCHEMA Esquema a volcar. -N, –exclude-schema=SCHEMA Esquema a excluir. -o, –oids Incluir OID de objetos en el volcado. -O, –no-owner No incluir el comando ALTER OWNER en el volcado. -p, –port=PORT Número de puerto del servidor de base de datos. -s, –schema-only No volcar los datos, solo los esquemas. -S, –superuser=NAME Nombre del superusuario de la base de datos. -t, –table=TABLE Tabla a volcar. -T, –exclude-table=TABLE Tabla a excluir. -U, –username=NAME Nombre de usuario para la conexión. -v, –verbose Mostrar información de progreso. -x, –no-privileges No incluir los comandos GRANT/REVOKE en el volcado. -Z, –compress=0-9 Comprimir el volcado con gzip. -?, –help Mostrar ayuda para esta opción. –version Mostrar información de versión. Para volcar todas las bases de datos:
pg_dumpall > backup.sql
Para restaurar la(s) base(s) de datos desde este archivo, puede usar:
psql -f db.out postgres
No es importante a qué base de datos se conecte aquí, ya que el archivo de script creado por pg_dumpall contendrá los comandos apropiados para crear y conectarse a las bases de datos guardadas. Una excepción es que si especificó –clean, debe conectarse inicialmente a la base de datos de postgres; la secuencia de comandos intentará eliminar otras bases de datos inmediatamente, y eso fallará para la base de datos a la que está conectado.
- pg_dump: Esta herramienta extrae una base de datos PostgreSQL en un archivo de script u otro archivo de almacenamiento. Su sintaxis es:
pg_dump [opciones de conexión][OPCIONES] NOMBRE_BASE_DE_DATOS
Es una utilidad para realizar copias de seguridad de una base de datos PostgreSQL. Realiza copias de seguridad coherentes incluso si la base de datos se utiliza al mismo tiempo. pg_dump no bloquea el acceso de otros usuarios a la base de datos (lectores o escritores).
Los volcados se pueden generar en formato de script o archivo de archivo. Los volcados de secuencias de comandos son archivos de texto sin formato que contienen los comandos SQL necesarios para reconstruir la base de datos al estado en el que se encontraba en el momento en que se guardó. Para restaurar desde un script de este tipo, lo introducimos en psql. Los archivos de script se pueden usar para reconstruir la base de datos incluso en otras máquinas y otras arquitecturas; con algunas modificaciones, incluso en otros productos de bases de datos SQL.
Los formatos de archivo de almacenamiento alternativos deben usarse con pg_restore para reconstruir la base de datos. Permiten que pg_restore sea selectivo sobre lo que se restaura, o incluso reordenar los elementos antes de restaurarlos. Los formatos de archivo de almacenamiento están diseñados para ser portátiles entre arquitecturas.
Cuando se usa con uno de los formatos de archivo de almacenamiento y se combina con pg_restore, pg_dump proporciona un mecanismo flexible de archivo y transferencia. pg_dump se puede usar para hacer una copia de seguridad de una base de datos completa, luego pg_restore se puede usar para examinar el archivo y/o seleccionar qué partes de la base de datos se restaurarán. Los formatos de archivo de salida más flexibles son el formato “personalizado” (-Fc) y el formato de “directorio” (-Fd). Permiten la selección y el reordenamiento de todos los elementos archivados, admiten la restauración paralela y están comprimidos de forma predeterminada. El formato de “directorio” es el único formato que admite volcados paralelos.
Las opciones de conexión son las mismas que para psql. Las opciones de volcado son:
| Opción | Descripción |
|---|---|
| -a, –data-only | No volcar los esquemas, solo los datos. |
| -b, –blobs | Incluir datos de tipo BLOB en el volcado. |
| -B, –no-blobs | No incluir datos de tipo BLOB en el volcado. |
| -c, –clean | Agregar comandos para eliminar objetos antes de crearlos. |
| -C, –create | Agregar comandos para crear la base de datos y los roles de base de datos. |
| -E, –encoding=ENCODING | Codificación de caracteres para el volcado. |
| -f, –file=file | Escribir el volcado a un archivo en lugar de la salida estándar. |
| -F | Formato de archivo de salida. Los valores válidos son: c (por defecto), t, p, d, o, a, h, custom, directory. |
| -j njobs, –jobs=njobs | Número de volcados paralelos a ejecutar. |
| -n, –schema=SCHEMA | Esquema a volcar. |
| -N, –exclude-schema=SCHEMA | Esquema a excluir. |
| -O, –no-owner | No incluir el comando ALTER OWNER en el volcado. |
| -s, –schema-only | No volcar los datos, solo los esquemas. |
| -S, –superuser=NAME | Nombre del superusuario de la base de datos. |
| -t, –table=TABLE | Tabla a volcar. |
| -T, –exclude-table=TABLE | Tabla a excluir. |
| -v, –verbose | Mostrar información de progreso. |
| -x, –no-privileges | No incluir los comandos GRANT/REVOKE en el volcado. |
| -Z, –compress=0-9 | Comprimir el volcado con gzip. |
| -?, –help | Mostrar ayuda para esta opción. |
Para volcar una base de datos llamada mydb en un archivo de script SQL:
$ pg_dump mydb > db.sql
Para volver a cargar un script de este tipo en una base de datos (recién creada) llamada newdb:
$ psql -d newdb -f db.sql
Para volcar una base de datos en un archivo de almacenamiento de formato personalizado:
$ pg_dump -Fc mydb > db.dump
Para volcar una base de datos en un archivo con formato de directorio:
$ pg_dump -Fd mydb -f dumpdir
Para volcar una base de datos en un archivo de formato de directorio en paralelo con 5 trabajos de trabajo:
$ pg_dump -Fd mydb -j 5 -f dumpdir
Para recargar un archivo comprimido en una base de datos (recién creada) llamada newdb:
$ pg_restore -d newdb db.dump
Para volver a cargar un archivo comprimido en la misma base de datos de la que se descargó, descartando el contenido actual de esa base de datos:
$ pg_restore -d postgres --clean --create db.dump
Para volcar una sola tabla llamada mytab:
$ pg_dump -t mytab mydb > db.sql
Para volcar todas las tablas cuyos nombres comienzan con emp en el esquema de Detroit, excepto la tabla llamada employee_log:
$ pg_dump -t 'detroit.emp*' -T detroit.employee_log mydb > db.sql
Para volcar todos los esquemas cuyos nombres comiencen con este u oeste y terminen en gsm, excluyendo cualquier esquema cuyos nombres contengan la palabra prueba:
$ pg_dump -n 'east*gsm' -n 'west*gsm' -N '*test*' mydb > db.sql
Lo mismo, usando la notación de expresiones regulares para consolidar los interruptores:
$ pg_dump -n '(east|west)*gsm' -N '*test*' mydb > db.sql
Para volcar todos los objetos de la base de datos excepto las tablas cuyos nombres comienzan con ts_:
$ pg_dump -T 'ts_*' mydb > db.sql
Para especificar un nombre en mayúsculas o en mayúsculas y minúsculas en -t y los modificadores relacionados, debe poner el nombre entre comillas dobles; de lo contrario, se doblará en minúsculas (ver patrones a continuación). Pero las comillas dobles son especiales para el shell, por lo que a su vez deben estar entre comillas. Por lo tanto, para volcar una sola tabla con un nombre de mayúsculas y minúsculas, necesita algo como
$ pg_dump -t "\"MixedCaseName\"" mydb > mytab.sql
El segundo tipo es el backup físico. La principal carcterística de este tipo de backup es que consiste en copiar los ficheros que pertenecen al cluster de PostgreSQL. Por lo tanto, si se produce un fallo en el sistema, se puede restaurar el cluster a partir de los ficheros de backup. Este tipo de backup es el más rápido y el más sencillo de realizar. Para realizar un backup físico de un cluster de PostgreSQL, se debe copiar el directorio de datos de PostgreSQL, que por defecto se encuentra en /var/lib/pgsql/data.
Los ficheros, al contrario que en los de backup lógico, no se encuentran en un formato legible por el usuario. Por lo tanto, no será posible restaurar la instancia en otro sistema operativo, arquitectura o versión de PostgreSQL. Dependiendo del método de backup que se utilice, la posibilidad de hacer un backup físico puede variar. También cabe destacar que no permitenn backups ni recuperaciones selectivas.
Existen dos técnicas para realizar un backup físico:
- Filesystem: consiste en copiar el directorio de datos de PostgreSQL. Es la técnica más sencilla y rápida de realizar. Sin embargo, para poder realizar este método, el servicio depe estar detenido. Pero de todas las técnicas que hemos visto, es la única que requiere que el servicio se pare para garantizar la copia consistente de los ficheros físicos.
Uno de sus inconvenientes es que necesitamos tener constancia de la forma en la que está distribuido el disco, es decir, saber las rutas físicas de los tablespaces. Así que lo primero que debemos hacer es consultar la ruta de los tablespaces con el comando:
$ psql -c "SELECT spcname, pg_tablespace_location(oid) FROM pg_tablespace;"
Y una vez sabidas las rutas, podríamos realizar el backup. También debemos tener en cuenta es que este método no permite las recuperaciones hasta un punto en el tiempo.
Podemos emplear dos métdos:
-
scp/cp: copiar el directorio de datos de PostgreSQL a un directorio de backup en otro servidor. Este método es el más sencillo de realizar, pero requiere que el servicio de PostgreSQL esté detenido. No debemos olvidar que, tras realizar la copia, debemos iniciar el servicio de PostgreSQL. Este método estaría totalmente descartado para bases de datos que requieren un alto nivel de disponibilidad o para aquellas que tengan un peso de datos muy elevado.
-
rsync: este método mejora el anterior, ya que no requiere que el servicio de PostgreSQL esté detenido. Para realizar el backup, se ejecuta el comando rsync con el parámetro -a, que realiza una copia recursiva y conserva los permisos, propietarios y fechas de los ficheros. Además, se añade el parámetro -z, que comprime los ficheros durante la copia. Por último, se añade el parámetro -v, que muestra el progreso de la copia. El comando quedaría de la siguiente forma:
rsync -avz /var/lib/pgsql/data/ backupserver:/var/lib/pgsql/backup/
- Archivado Continuado: esta es la única técnica que permite que se pueda recuperar hasta un punto en el tiempo. Para realizar este tipo de backup, se debe configurar el parámetro archive_mode en on. Este parámetro permite que se creen ficheros de backup cada vez que se realiza un checkpoint. Por defecto, se crean en el directorio pg_xlog, que se encuentra en el directorio de datos de PostgreSQL.
Para realizar una prueba de las herramientas de copia de seguridad, vamos a realizar la copia con pg_dump de la base de datos SCOTT. Para ello, nos logueamos en la base de datos SCOTT y ejecutamos el siguiente comando:
mkdir /etc/postgresql-backups
pg_dump scott > /etc/postgresql-backups/scott`date +"%Y%m%d_%H%M%S"`.sql
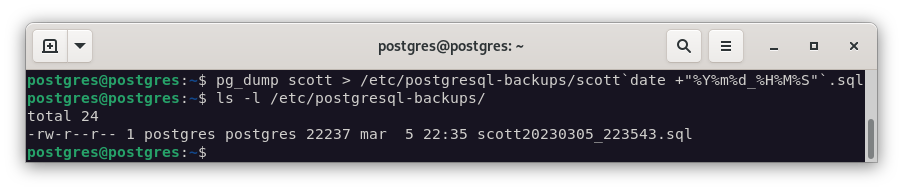
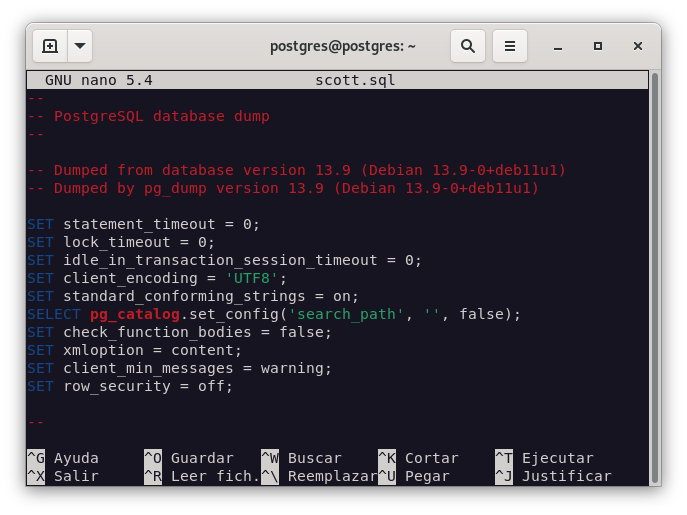
Una vez finalizada la copia, podemos comprobar que se ha creado el fichero scott.sql en el directorio de trabajo. Para restaurar la base de datos, debemos crear una nueva base de datos con el mismo nombre.
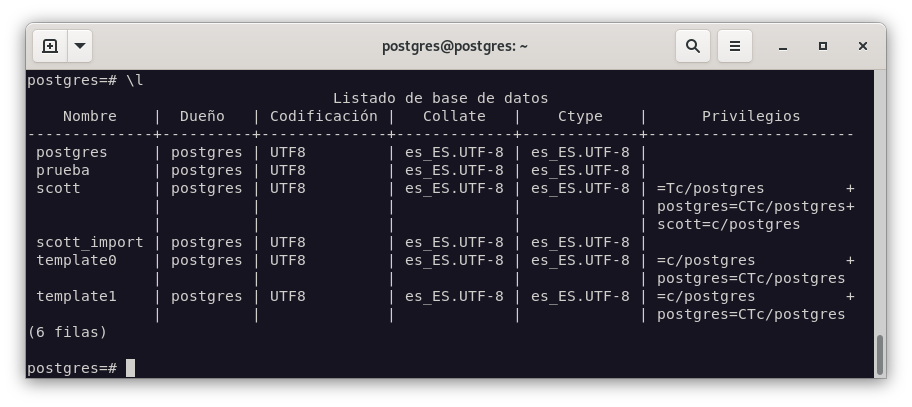
Como podemos ver, la base de datos BACKUP no existe. Por lo tanto, la creamos, y verificamos que está completamente vacía:
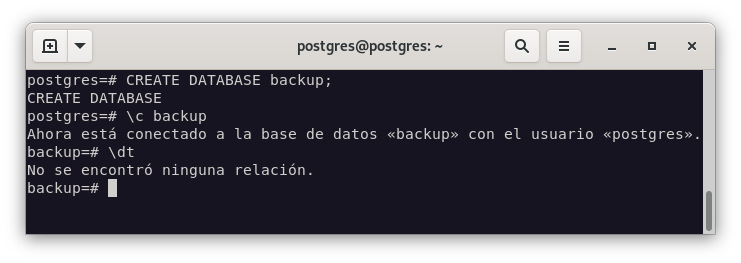
psql -f /etc/postgresql-backup/scott.sql backup
Una vez finalizada la restauración, podemos comprobar que la base de datos SCOTT se ha restaurado correctamente.
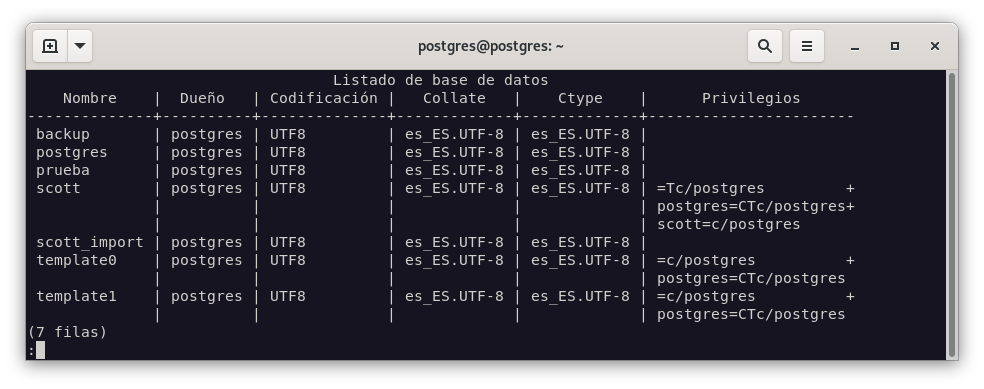
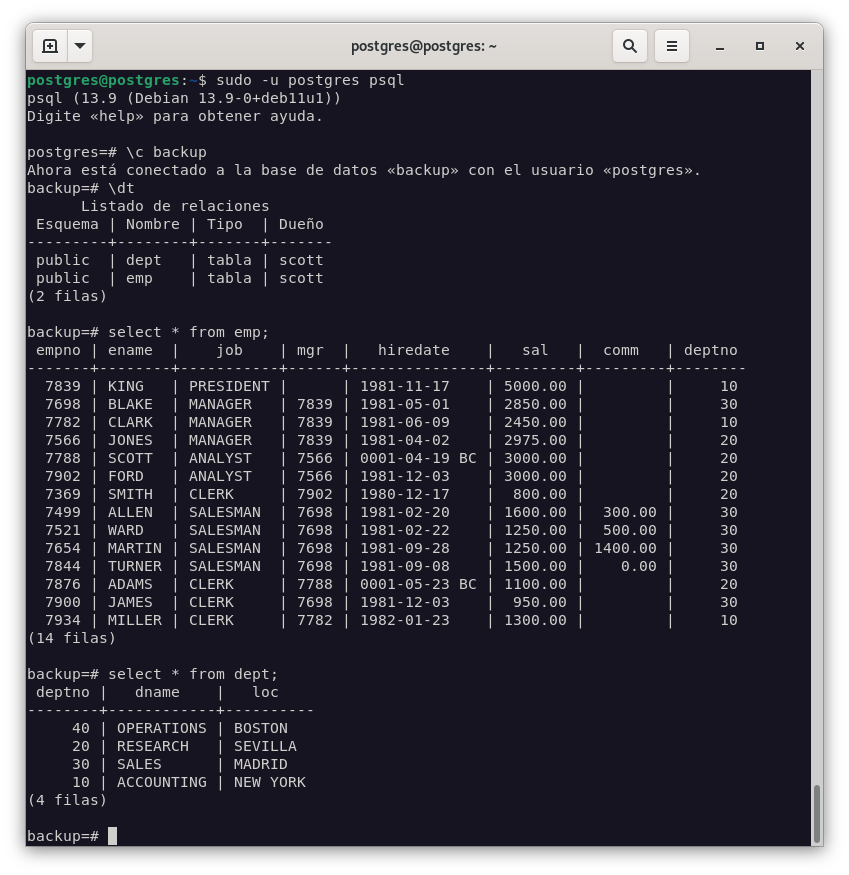

Ejercicio 7
Documenta el empleo de las herramientas de copia de seguridad y restauración de MySQL.
Existen varias formas de realizar una copia de seguridad de una base de datos MySQL o MarriaDB,auque el más común y recomendado es el uso de mysqldump. Como podéis ver en la entrada de movimientos de datos, hicimos uso de mysqldump para realizar los movimientos de datos entre bases de datos. Puede ser tanto una exportación parcial como una total.
Gracias a su multitud de parámetros, que lo hacen muy configurable:
| Parámetro | Descripción |
|---|---|
| –bind-address | Dirección IP del servidor MySQL |
| –compress | Comprime el fichero de salida |
| –login-path | Nombre del fichero de configuración de MySQL |
| –pipe, -W | Conexión con el servidor usando el nombre de pipe |
| –port | Puerto de conexión con el servidor MySQL |
| –no-create-db | No crea la base de datos |
| –no-create-info | No crea la información de las tablas |
En su documentación oficial podemos encontrar más información sobre los parámetros que podemos usar.
Vale pero, ¿qué tipos de backups podemos realizar con mysqldump?:
- Backup total: Esta opción es muy oportuna en el caso de tener un servidor con varias bases de datos pero solo queremos realizar la copia de seguridad de una de ellas. Para ello, deberemos hacer la ecportación completa de todos los datos de la base de datos, incluyendo datos, triggers, procedimientos, vistas, estructura… Con el siguiente comando realizaríamos un backup total de la base de datos, siendo el nombre del fichero resultante el nombre de la base de datos y la fecha de la copia de seguridad:
mysqldump -v --opt --events --routines --triggers --default-character-set=utf8 -u your_username -p your_db_name > db_backup_your_db_name_`date +%Y%m%d_%H%M%S`.sql
Para darle pas seguridad a la copia de seguridad, podemos incluir después del nombre de la base de datos la opción -c | --compress para comprimir el fichero de salida.
mysqldump --opt --events --routines --triggers --default-character-set=utf8 -u your_username --password=your_password your_db_name | gzip -c > db_backup_your_db_name_`date +%Y%m%d_%H%M%S`.sql.gz
En caso de que solo querramos exportar la estructura de la base de datos, podemos usar el siguiente comando:
mysqldump -v --opt --no-data --default-character-set=utf8 -u your_username -p your_db_name > db_structure_your_db_name_`date +%Y%m%d_%H%M%S`.sql
Pero en el caso de que solo querramos el contenido de datos que contienen las tablas,es decir, solo los datos que se han generado con las sentencias insert, podemos usar el siguiente comando:
mysqldump -v --opt --no-create-info --skip-triggers --default-character-set=utf8 -u your_username -p your_db_name > db_data_your_db_name_`date +%Y%m%d_%H%M%S`.sql
- Backup parcial: Esta opción, como su nombre indica, se realiza si solo nos interesa hacer una copia de un conjunto de tablas y lo podemos hacer de dos maneras: o especificamos una por una las tablas de las que queremos realizar la copia de seguridad, o realizamos una copia completa usando el parámetro
--ignore-tablepara que, como suguiere el parámetro, se realiza la copia completa ignorando las tablas mencionadas.
Si lo que queremos es realizar soloun subconjunto de tablas, podríamos emplear el siguiente comando:
mysqldump -v --opt --default-character-set=utf8 -u your_username -p your_db_name table1 table2 table3 > db_tables_your_db_name_`date +%Y%m%d_%H%M%S`.sql
Si lo que queremos es realizar una copia de seguridad de todas las tablas excepto de unas cuantas, podríamos emplear el siguiente comando:
mysqldump -v --opt --default-character-set=utf8 -u your_username -p --ignore-table=table1 --ignore-table=table2 --ignore-table=table3 your_db_name > db_tables_your_db_name_`date +%Y%m%d_%H%M%S`.sql
Este último caso es muy útil cuando las tablas que nos interesan son más de las que no nos interesan.
- Backup remoto: Como su nombre indica, lo podemos realizar accediendo al servidor MySQL desde otro servidor. Para ello, deberemos tener instalado el cliente MySQL en el servidor desde el que queremos realizar la copia de seguridad.
Para realizar la copia de seguridad, deberemos usar el siguiente comando:
mysqldump -v --opt -h mysql.example.com -P 3306 --compress --events --routines --triggers --default-character-set=utf8 -u your_username -p your_db_name > db_backup_your_db_name_`date +%Y%m%d_%H%M%S`.sql
Otra forma sería conectándonos al servidor a traves de ssh:
ssh ssh_username@server "mysqldump -v --opt --events --routines --triggers --default-character-set=utf8 -u your_username --password=your_password your_db_name | gzip -c" > db_backup_your_db_name_`date +%Y%m%d_%H%M%S`.sql.gz
Para realizar una prueba de restauración, vamos a utilizar la base de datos de scott que tenemos en nuestro servidor MySQL. Para ello, vamos a crear una base de datos de prueba y vamos a importar la base de datos de scott en ella.
mysql -u root -p
mysql> create database scott_full;
mysql> create database scott_partial;
mysql> create database scott_structure;
mysql> exit
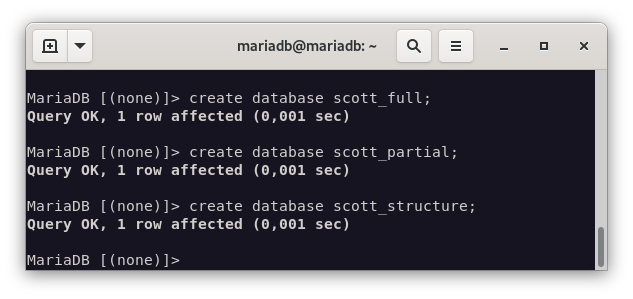
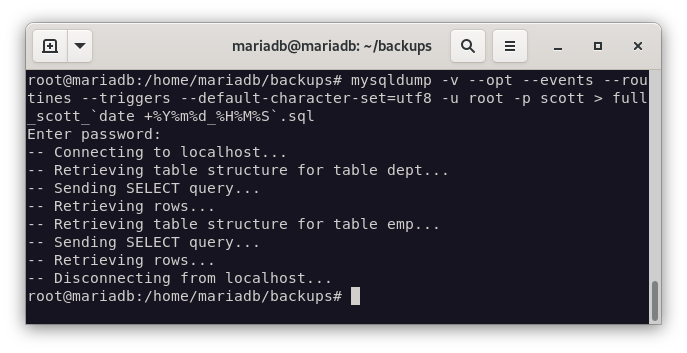
Ahora vamos a realizar la copia de seguridad de la base de datos de scott completa.
mysqldump -v --opt --events --routines --triggers --default-character-set=utf8 -u root -p scott > full_scott_`date +%Y%m%d_%H%M%S`.sql
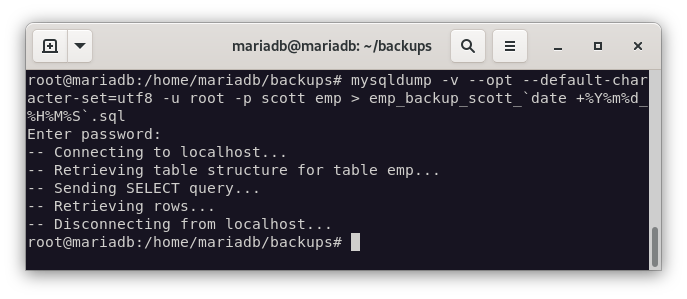
Ahora vamos a realizar la copia de seguridad de la base de datos de scott, pero solo de las tabla emp:
mysqldump -v --opt --default-character-set=utf8 -u root -p scott emp > emp_backup_scott_`date +%Y%m%d_%H%M%S`.sql
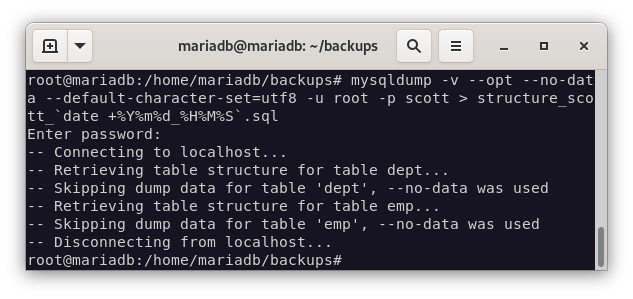
Y ahora vamos a realizar la copia de seguridad de la estructura de la base de datos de scott:
mysqldump -v --opt --no-data --default-character-set=utf8 -u root -p scott > structure_scott_`date +%Y%m%d_%H%M%S`.sql
Como podemos ver, los 3 ficheros se han creado correctamente. Ahora, para comprobar que las copias de seguridad se han realizado correctamente, vamos a restaurar las copias de seguridad en su correspondiente base de datos para las pruebas pertinentes.
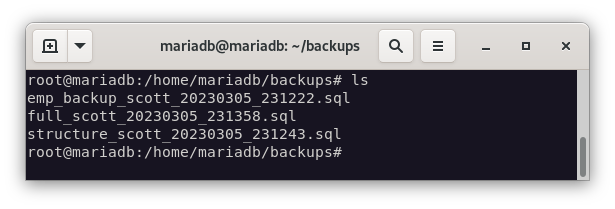
# Restauramos la copia de seguridad completa
$ mysql -u root -p scott_full < full_scott_20230305_231358.sql
# Restauramos la copia de seguridad de la tabla emp
$ mysql -u root -p scott_partial < emp_backup_scott_20230305_231222.sql
# Restauramos la copia de seguridad de la estructura de la base de datos
$ mysql -u root -p scott_structure < structure_scott_0230305_231343.sql
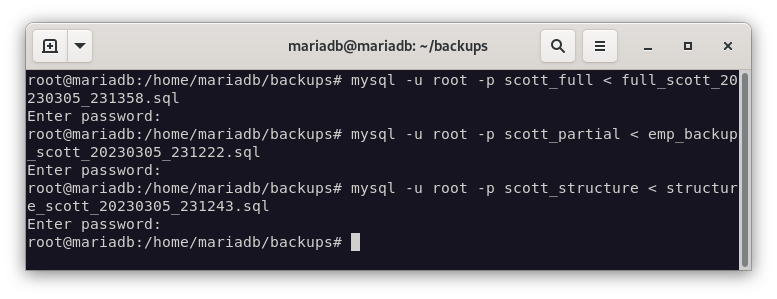
Y como podemos ver en la siguiente imagen, se han restaurado correctamente las copias de seguridad.
-
Mostramos que las bases de datos se encuentran creadas.
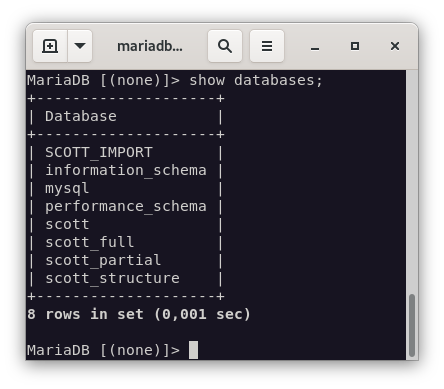
-
Scott_full
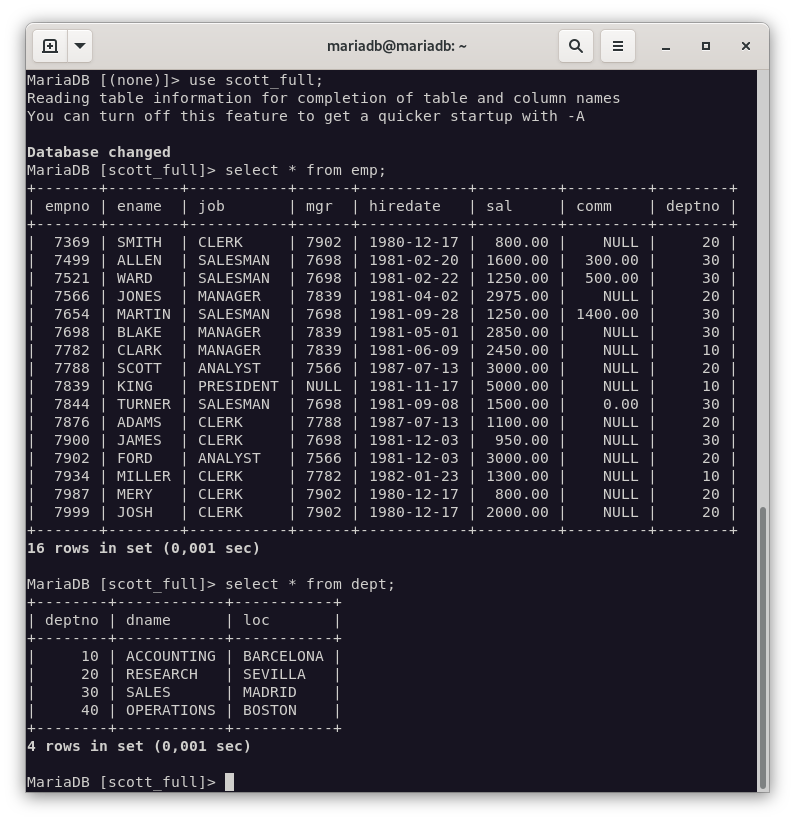
-
Scott_partial
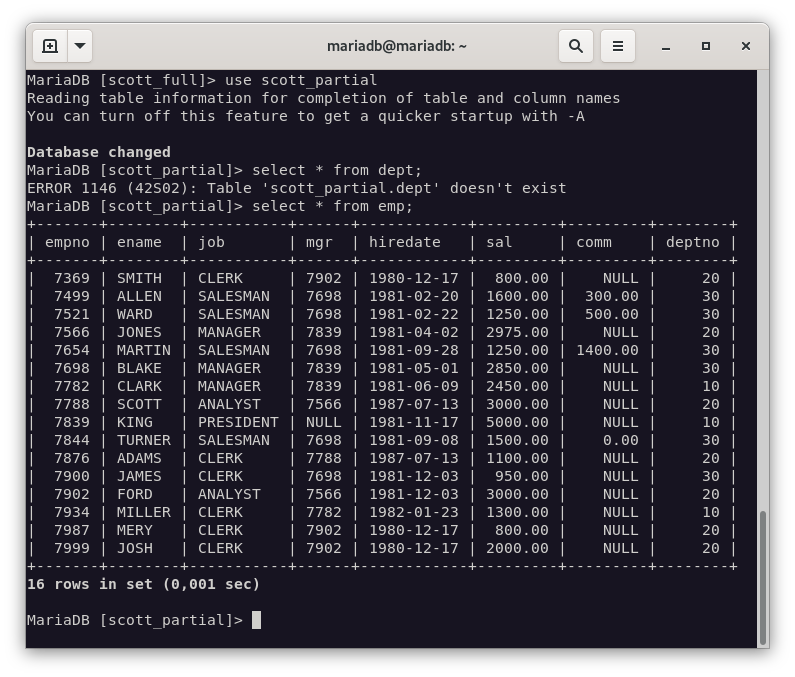
-
Scott_structure
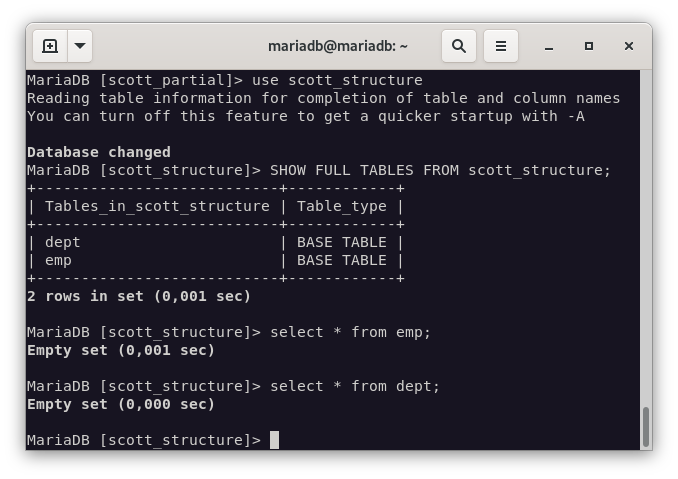

Ejercicio 8
Documenta el empleo de las herramientas de copia de seguridad y restauración de MongoDB.
Para realizar copias de seguridad de MongoDB, podemos usar la herramienta mongodump que nos permite realizar copias de seguridad de la base de datos completa o de una colección en concreto.
EL primer paso es crear un directorio donde se almacenarán las copias de seguridad que realizaremos de las bases de datos. Si estamos gestionando varias bases de datos, deberemos crear un directorio para cada una de ellas, para de esta forma poder diferenciar las copias de seguridad de cada una de ellas.
mkdir -p /var/backups/mongodbLo idóneo será que el nombre del fichero de la copia de seguridad sea el nombre de la base de datos que estamos copiando, junto con la fecha en la que se ha realizado la copia de seguridad.
mongodump -h ip_base_server -d your_db_name -o /var/backups/mongodb/your_db_name_`date +"%Y%m%d_%H%M%S"`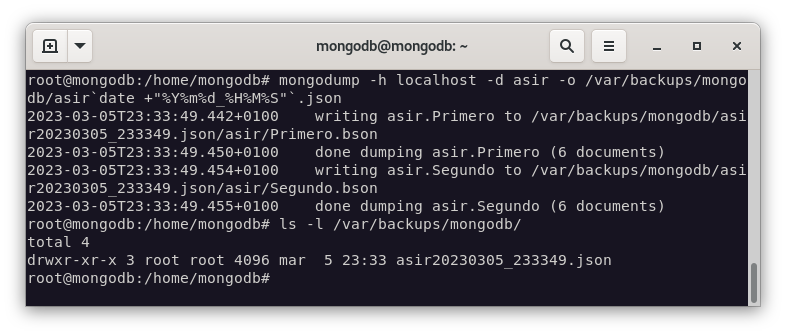
Para que la copia de seguridad se realice de forma automática, lo realizaremos mediante un script que se ejecutará cada cierto tiempo, que progararemos en el crontab del sistema. Por ello, lo primero que haremos será crear el script que se encargará de realizar la copia de seguridad y le damos permisos de ejecución.
$ nano /opt/scripts/mongodb_backup.sh
sudo chmod +x /opt/scripts/mongodb_backup.shSi lo que queremos es un scritp que nos permita elegir el directorio de destino de la copia de seguridad, podemos usar el siguiente script:
#!/bin/bash
#Autori: María Jesús Alloza Rodríguez
#Versión: 1.0
#Descripción: Script para realizar copias de seguridad de MongoDB
#Fecha de creación: 02/03/2023
echo "Starting MongoDB Backup"
echo "------------------------"
##Función para elegir el directorio de destino de la copia de seguridad
read -p "Introduce el directorio de destino de la copia de seguridad: " DEST
#Variable
DESTINO="/var/backups/mongodb/"$DEST
#Comprobación de que el directorio de destino existe
if [ -d $DESTINO ]; then
echo "El directorio $DESTINO existe"
else
echo "El directorio $DESTINO no existe"
echo "Creando directorio $DESTINO"
mkdir -p $DESTINO
fi
#Elección de la base de datos a copiar
read -p "Introduce el nombre de la base de datos a copiar: " DB
#Comprobación de que la base de datos existe
if [ -d /var/lib/mongodb/$DB ]; then
echo "La base de datos $DB existe"
else
echo "La base de datos $DB no existe"
exit 1
fi
#Realización de la copia de seguridad
echo "Realizando copia de seguridad de la base de datos $DB"
mongodump -h localhost -d $DB -o $DESTINO/$DB_`date +"%Y%m%d_%H%M%S".json`
echo "Copia de seguridad realizada con éxito"
echo "--------------------------------------"Visto este script, vamos a realizar uno, que realice una copia de seguridad de la base de datos asir cada día a las 00:00 horas.
nano /opt/scripts/asir_backup.sh#!/bin/bash
#Autora: María Jesús Alloza Rodríguez
#Versión: 1.0
#Descripción: Script para realizar copias de seguridad de la base de datos Asir
echo "Starting MongoDB Backup"
echo "------------------------"
mongodump -h localhost -d asir -o /var/backups/mongodb/asir_`date +"%Y%m%d_%H%M%S"`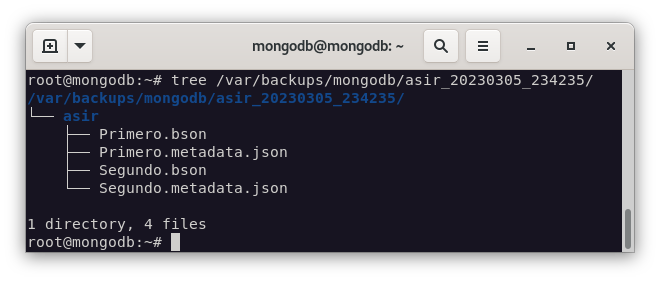
Una vez creado el script, lo programamos en el crontab del sistema para que se ejecute cada día a las 00:00 horas.
$ crontab -e
0 0 * * * /opt/scripts/asir_backup.shPara restaurar una copia de seguridad de MongoDB, podemos usar la herramienta mongorestore que nos permite restaurar una base de datos completa o una colección en concreto.
Para restaurar una base de datos completa, lo que haremos será ejecutar el siguiente comando:
$ mongorestore --db asir_copia --verbose /var/backups/mongodb/asir_20230305_234235/asir/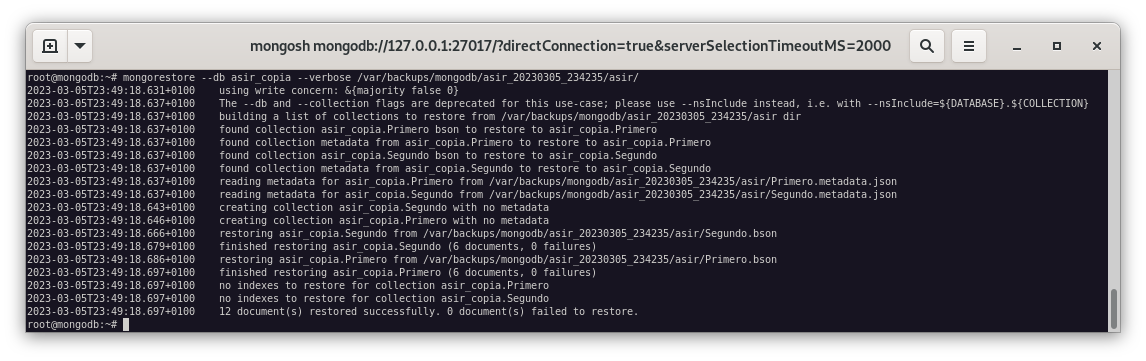
Como podemos observar, la base de datos asir_copia se ha restaurado correctamente.
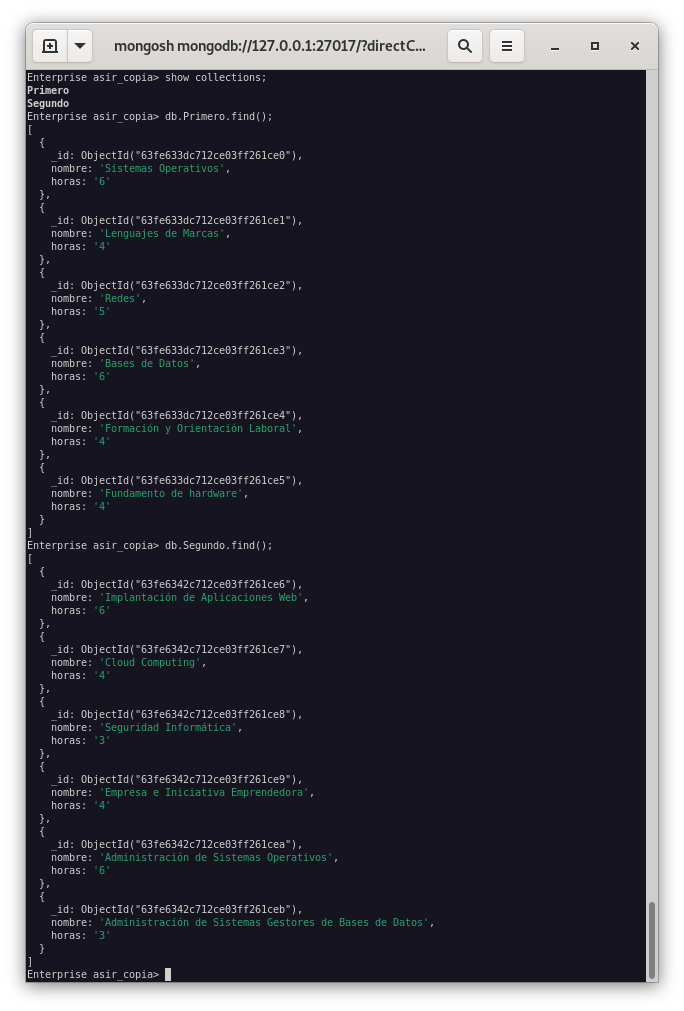
Para restaurar una colección en concreto, lo que haremos será ejecutar el siguiente comando:
$ mongorestore --db asir_collection --collection Primero /var/backups/mongodb/asir_20230305_234235/asir/Primero.bson 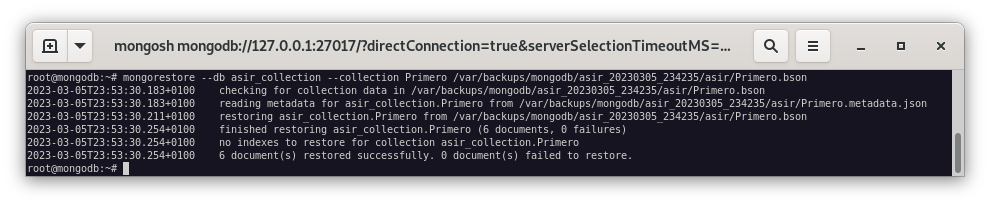
Como podemos observar, la colección Primero de la base de datos asir_collection se ha restaurado correctamente, pero no se ha restaurado la colección Segundo.
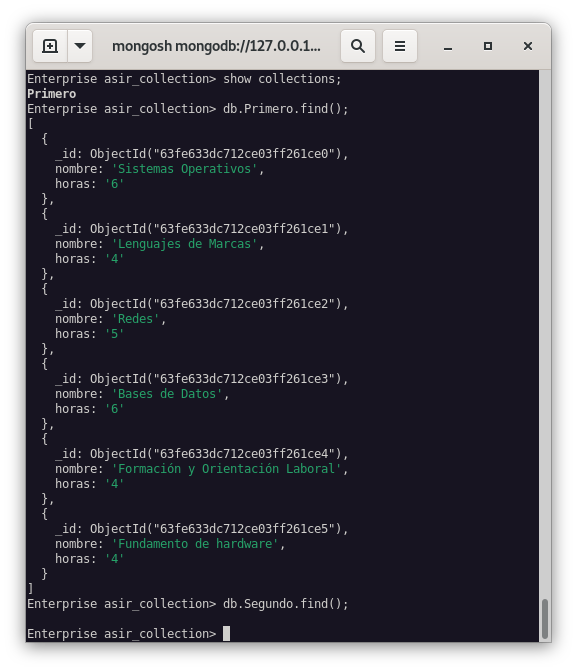
Como podemos ver en esta imagen final, ambas bases de datos, asir_copia y asir_collection, se han restaurado correctamente.
Pero si lo que queremos es realizar una restauración de una copia de seguridad en concreta de una base de datos concreta (en este caso la base de datos asir), podemos usar el siguiente script:
#!/bin/bash
#Autora: María Jesús Alloza Rodríguez
#Versión: 1.0
#Descripción: Script para realizar copias de seguridad de la base de datos Asir
echo "Las copias de seguridad de la base de datos asir son: "
echo "----------------------------------------------------"
DIRECTORIO="/var/backups/mongodb/asir"
#Listado de las copias de seguridad de la base de datos asir
ls $DIRECTORIO
echo "----------------------------------------------------"
read -p "Introduce el nombre de la copia de seguridad que quieres restaurar: " COPIA
mongoimport -u admin --db asir --file $DIRECTORIO$COPIA
echo "Restauración realizada con éxito"